



分析&回答
kafka的一个基本架构:多个broker组成,一个broker是一个节点;你创建一个topic,这个topic可以划分成多个partition,每个partition可以存在于不同的broker上面,每个partition存放一部分数据。这是天然的分布式消息队列。
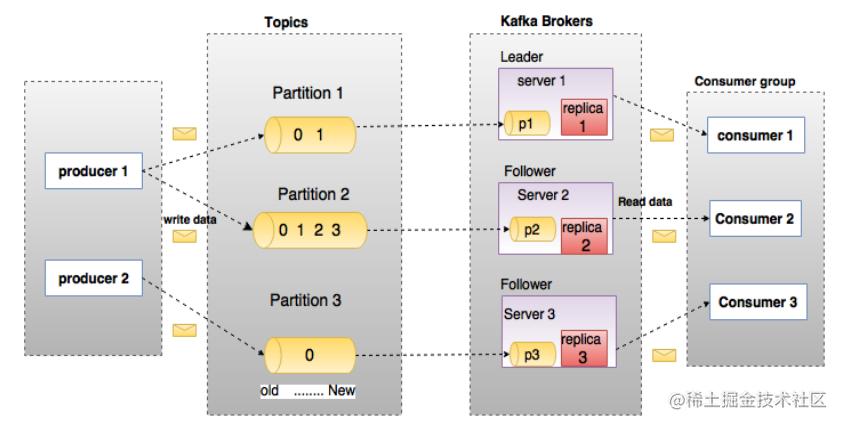
kafka在0.8之后,提过了HA机制,也就是replica副本机制。每个partition的数据都会同步到其他机器上,形成自己的replica副本。然后所有的replica副本会选举一个leader出来,那么生产者消费者都和这个leader打交道,其他的replica就是follower。写的时候,leader会把数据同步到所有follower上面去,读的时候直接从leader上面读取即可。
为什么只能读写leader:因为要是你可以随意去读写每个follower,那么就要关心数据一致性问题,系统复杂度太高,容易出问题。kafka会均匀度讲一个partition的所有数据replica分布在不同的机器上,这样就可以提高容错性。
这样就是高可用了,因为如果某个broker宕机 了,没事儿,那个broker的partition在其他机器上有副本,如果这上面有某个partition的leader,那么此时会重新选举出一个现代leader出来,继续读写这个新的leader即可。
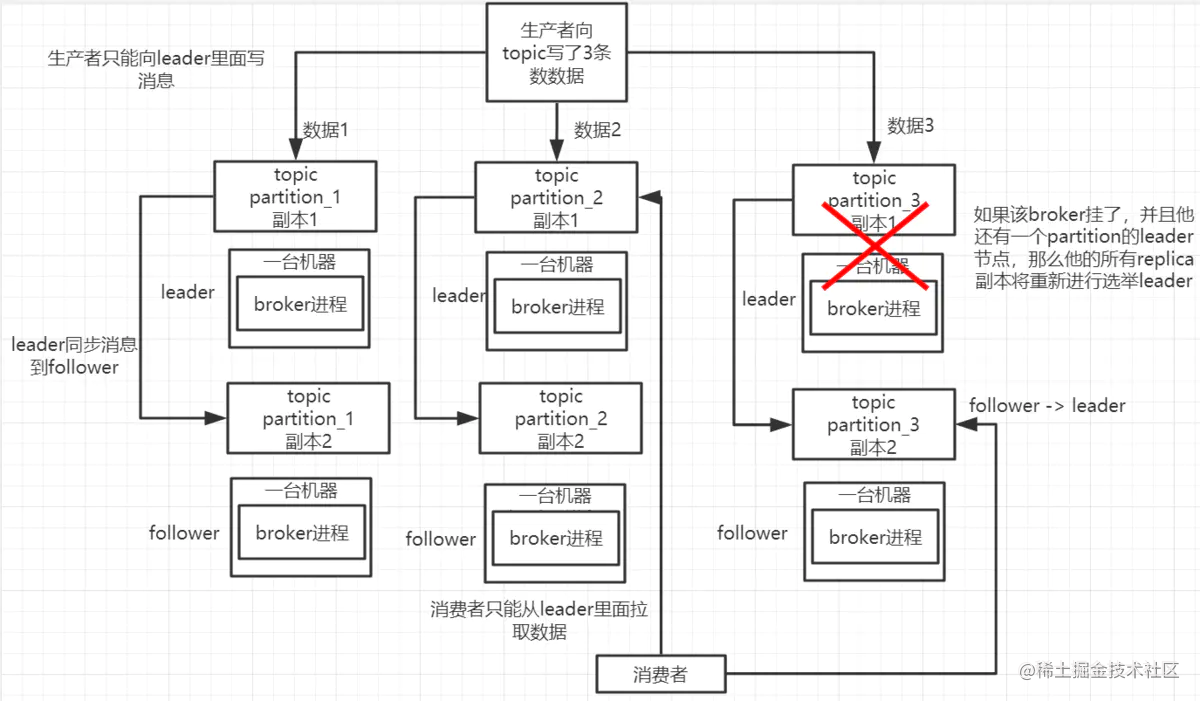
- 写消息: 写数据的时候,生产者就写leader,然后leader将数据落到磁盘上之后,接着其他follower自己主动从leader来pull数据。一旦所有follower同步好了数据,就会发送ack个leader,leader收到了所有的follower的ack之后,就会返回写成功的消息给消息生产者。(这只是一种模式,可以调整)。
- 读数据:消费数据的时候,只会从leader进行消费。但是只有一个消息已经被所有follower都同步成功返回ack的时候,这个消息才会被消费者读到。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




