



1)Java 中能创建 volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组。我的意思是,如果改变引用指向的数组,将会受到 volatile 的保护,但是如果多个线程同时改变数组的元素,volatile 标示符就不能起到之前的保护作用了。
2)volatile 能使得一个非原子操作变成原子操作吗?
一个典型的例子是在类中有一个 long 类型的成员变量。如果你知道该成员变量会被多个线程访问,如计数器、价格等,你最好是将其设置为 volatile。为什么?因为 Java 中读取 long 类型变量不是原子的,需要分成两步,如果一个线程正在修改该 long 变量的值,另一个线程可能只能看到该值的一半(前 32 位)。但是对一个 volatile 型的 long 或 double 变量的读写是原子。
3)volatile 修饰符的有过什么实践?
一种实践是用 volatile 修饰 long 和 double 变量,使其能按原子类型来读写。double 和 long 都是64位宽,因此对这两种类型的读是分为两部分的,第一次读取第一个 32 位,然后再读剩下的 32 位,这个过程不是原子的,但 Java 中 volatile 型的 long 或 double 变量的读写是原子的。volatile 修复符的另一个作用是提供内存屏障(memory barrier),例如在分布式框架中的应用。简单的说,就是当你写一个 volatile 变量之前,Java 内存模型会插入一个写屏障(write barrier),读一个 volatile 变量之前,会插入一个读屏障(read barrier)。意思就是说,在你写一个 volatile 域时,能保证任何线程都能看到你写的值,同时,在写之前,也能保证任何数值的更新对所有线程是可见的,因为内存屏障会将其他所有写的值更新到缓存。
4)volatile 类型变量提供什么保证?
volatile 变量提供顺序和可见性保证,例如,JVM 或者 JIT为了获得更好的性能会对语句重排序,但是 volatile 类型变量即使在没有同步块的情况下赋值也不会与其他语句重排序。 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。某些情况下,volatile 还能提供原子性,如读 64 位数据类型,像 long 和 double 都不是原子的,但 volatile 类型的 double 和 long 就是原子的。
5) 10 个线程和 2 个线程的同步代码,哪个更容易写?
从写代码的角度来说,两者的复杂度是相同的,因为同步代码与线程数量是相互独立的。但是同步策略的选择依赖于线程的数量,因为越多的线程意味着更大的竞争,所以你需要利用同步技术,如锁分离,这要求更复杂的代码和专业知识。
6)你是如何调用 wait()方法的?使用 if 块还是循环?为什么?
wait() 方法应该在循环调用,因为当线程获取到 CPU 开始执行的时候,其他条件可能还没有满足,所以在处理前,循环检测条件是否满足会更好。下面是一段标准的使用 wait 和 notify 方法的代码:
// The standard idiom for using the wait method
synchronized (obj) {
while (condition does not hold)
obj.wait(); // (Releases lock, and reacquires on wakeup)
... // Perform action appropriate to condition
}
参见 Effective Java 第 69 条,获取更多关于为什么应该在循环中来调用 wait 方法的内容。
7)什么是多线程环境下的伪共享(false sharing)?
伪共享是多线程系统(每个处理器有自己的局部缓存)中一个众所周知的性能问题。伪共享发生在不同处理器的上的线程对变量的修改依赖于相同的缓存行,如下图所示:
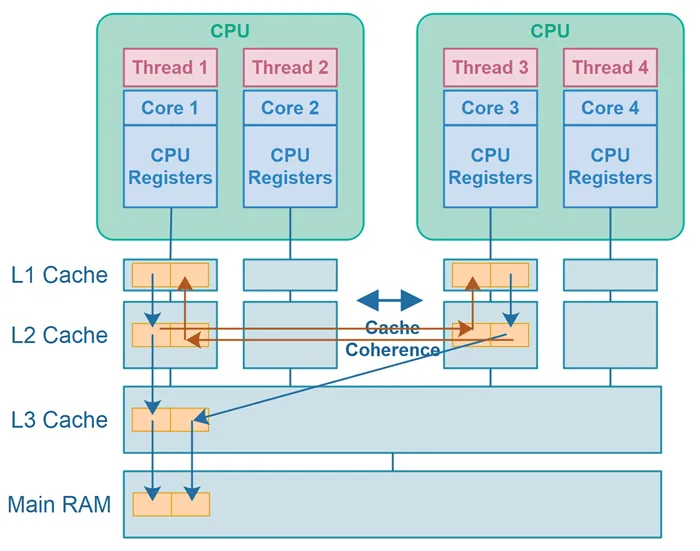
伪共享问题很难被发现,因为线程可能访问完全不同的全局变量,内存中却碰巧在很相近的位置上。如其他诸多的并发问题,避免伪共享的最基本方式是仔细审查代码,根据缓存行来调整你的数据结构。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




