



一、单选题
1、列表L1中全是整数,小明想将其中所有奇数都增加1,偶数不变,于是编写了如下图所示的代码。 请问,图中红线处,代码应该是?( )

A、x || 2
B、x ^ 2
C、x && 2
D、x % 2
解析:【喵呜刷题小喵解析】根据题目描述,小明想要将列表L1中所有的奇数都增加1,偶数保持不变。首先,我们需要找到列表L1中的所有奇数。在Python中,判断一个数是否为奇数可以使用模运算符 `%`,即如果 `x % 2 == 1`,则x是奇数。因此,我们可以使用列表推导式来生成一个新的列表,其中包含了所有需要增加1的奇数。具体来说,新的列表应该是 `[x + 1 if x % 2 == 1 else x for x in L1]`。在这个列表中,如果x是奇数(即 `x % 2 == 1`),则将其增加1,否则保持不变。因此,红线处的代码应该是 `L1 = [x + 1 if x % 2 == 1 else x for x in L1]`。选项D与此相符,因此是正确答案。
2、小明为了学习选择排序的算法,编写了下面的代码。针对代码中红色文字所示的**一、二、三**处,下面说法正确的是?( ) a = [8,4,11,3,9] count = len(a) for i in range(count-1): mi = i for j in range(i+1,count): if a[mi] > a[j]: #代码一 mi = j #代码二 if i!=mi: a[mi],a[i] = a[i],a[mi] #代码三 print(a)
A、如果找到更大的元素,则记录它的索引号。
B、如果找到更小的元素,则记录它的索引号。
C、在一趟选择排序后,不管是否找到更小的元素,mi所在元素都得与i所在的元素发生交换。
D、代码三所在的行必然要运行。
解析:【喵呜刷题小喵解析】在选择排序算法中,目的是通过每次从未排序的元素中选取最小(或最大)的一个元素,与已排序序列的末尾元素进行交换,使得已排序序列长度+1。在给出的代码中,对于每一趟排序,通过内层循环找到未排序部分的最小元素的索引,即mi。当内层循环结束后,如果i不等于mi,说明找到了更小的元素,则需要进行交换。因此,当代码执行到"代码三"所在行时,mi的值代表的是当前未排序部分的最小元素的索引。A选项表示"如果找到更大的元素,则记录它的索引号",这与选择排序的原理不符,因为选择排序是找最小(或最大)元素,而不是最大元素。C选项表示"在一趟选择排序后,不管是否找到更小的元素,mi所在元素都得与i所在的元素发生交换",这是错误的,只有当i不等于mi时,才需要进行交换。D选项表示"代码三所在的行必然要运行",这也是错误的,只有当i不等于mi时,才需要执行代码三所在的行。因此,正确答案是B选项,即"如果找到更小的元素,则记录它的索引号"。
3、小明编写了一段演示插入排序的代码,代码如下。请问红色“缺失代码”处,应该填写哪段代码?( ) a = [8,4,11,3,9] count = len(a) for i in range(1, count): j = i b = a[i] while j>0 and b a[j] = a[j-1] 缺失代码 a[j] = b print(a)
A、j=j-1
B、j=j+1
C、j=i+1
D、j=i-1
解析:【喵呜刷题小喵解析】:在插入排序中,我们需要将当前元素(b)插入到已排序的序列中。在插入的过程中,如果当前元素(b)小于其前一个元素,则我们需要将前一个元素向右移动,直到找到合适的位置插入当前元素。所以,缺失的代码处应该是`a[j-1] > b`,表示当前元素(b)应该插入到`a[j-1]`的右侧。因此,正确选项是A,即`j = j - 1`。
4、在计算机中,信息都是采用什么进行存储?( )
A、二进制数
B、八进制数
C、十进制数
D、十六进制数
解析:【喵呜刷题小喵解析】:在计算机中,信息都是采用二进制数进行存储。二进制数是由0和1两个数字组成的数字系统,它是最基本的数字系统之一,也是计算机内部处理信息的基础。计算机中的所有信息,包括数字、文字、图像等,最终都是以二进制数的形式进行存储和处理的。因此,选项A“二进制数”是正确的答案。
5、十进制数(100)10,转化为二进制数为( )2?
A、0010011
B、1010001
C、1100100
D、0101100
解析:【喵呜刷题小喵解析】十进制数转换为二进制数,需要将十进制数除以2,取余数,然后将商继续除以2,如此反复,直到商为0为止。将得到的余数从下到上排列,即可得到二进制数。将100除以2,得到商50和余数0,再将50除以2,得到商25和余数0,继续将25除以2,得到商12和余数1,再将12除以2,得到商6和余数0,继续将6除以2,得到商3和余数0,再将3除以2,得到商1和余数1,最后将1除以2,得到商0和余数1,所以100的二进制表示为1100100。因此,选项C是正确的。
6、十六进制数每一位至多可以表示几位二进制位?( )
A、2
B、3
C、4
D、16
解析:【喵呜刷题小喵解析】:在十六进制中,每一位可以由0-9这十个数字和A-F这六个字母来表示,每个字母代表4位二进制数。因此,十六进制数每一位至多可以表示4位二进制位。所以正确答案为C。
7、八进制数(35)8,转化为十进制数为( ) 10?
A、100011
B、110001
C、232
D、29
解析:【喵呜刷题小喵解析】八进制数(35)8,转化为十进制数的过程如下:* 3在八进制中等于3*8^0 = 3* 5在八进制中等于5*8^1 = 40因此,八进制数(35)8等于3*8^0 + 5*8^1 = 3 + 40 = 43。再将43转化为十进制数,43等于4*10^1 + 3*10^0 = 40 + 3 = 43。所以,八进制数(35)8转化为十进制数为43,即选项D 29。
8、执行代码a=min(3,2,4.3),变量a的值是?( )
A、3
B、2
C、4.3
D、4
解析:【喵呜刷题小喵解析】在Python中,min函数返回的是传入参数中的最小值。在本题中,min(3,2,4.3)返回的是2,因为2是这些数中的最小值。因此,变量a的值是2,选项B正确。
9、print(max('python+'))的运行结果是?( )
A、'p'
B、p
C、'y'
D、y
解析:【喵呜刷题小喵解析】:在Python中,`max()`函数用于找出可迭代对象中的最大值。在给定的例子中,`max('python+')`实际上试图找出字符串`'python+'`中的最大值字符,但是字符串并不是一个数字或者可以进行比较的类型,因此这会产生一个TypeError。如果忽略这个错误,`max()`函数会返回字符串中的第一个字符。在这个例子中,第一个字符是'p',因此输出会是'p'。但是,这个答案基于一个假设,即代码可以成功运行,而实际上它会引发一个错误。在真实环境中,这样的代码是不应该被执行的。因此,最佳答案应该是选项D,即'y',因为如果忽略错误,'y'会是字符串中的第二个字符,而'p'并不在选项中。然而,这仍然是一个有误导性的问题,因为它假设了一个不可能发生的场景。在真实的Python环境中,这样的代码会引发一个错误,而不是返回'p'或'y'。
10、a=5.12596 print(round(a,2))运行结果是?( )
A、5
B、5.1
C、5.12
D、5.13
解析:【喵呜刷题小喵解析】在Python中,`round()`函数用于对浮点数进行四舍五入。`round(a, 2)`表示将浮点数`a`四舍五入到小数点后两位。在这个问题中,`a`的值为5.12596,四舍五入到小数点后两位的结果是5.13。因此,`print(round(a, 2))`的运行结果是5.13,选项D是正确的。
11、type([{2.6}])运行的结果是?( )
A、float
B、dict
C、True
D、list
解析:【喵呜刷题小喵解析】:题目中的表达式“2.6”是一个浮点数,它不是一个字典、布尔值或列表。因此,运行结果为D,即“list”。但实际上,2.6是一个浮点数,而不是列表,所以这里的选项设置可能存在问题。如果题目是要考察对基本数据类型的识别,那么正确答案应该是“A float”。
12、执行如下代码 a=[1,2,3,4] print(list(enumerate(a))) 运行结果是?( )
A、((0, 1), (1, 2), (2, 3), (3, 4))
B、[(0, 1), (1, 2), (2, 3), (3, 4)]
C、[1,2,3,4]
D、(1,2,3,4)
解析:【喵呜刷题小喵解析】题目中执行的是以下代码:```pythona=[1,2,3,4]print(list(enumerate(a)))```enumerate(a)` 是一个 Python 内置函数,它返回元组,每个元组包含索引和对应元素。`enumerate(a)` 的结果是一个迭代器,使用 `list()` 函数将其转化为列表。列表的每个元素都是一个元组,元组的第一个元素是索引,第二个元素是原列表的对应元素。所以,代码执行后的结果应为 `[(0, 1), (1, 2), (2, 3), (3, 4)]`,对应选项 B。
13、set('hello')运行结果是?( )
A、('h', 'e', 'l', 'l','o')
B、{'h', 'e', 'l', 'l','o'}
C、{'e', 'h', 'l', 'o'}
D、('e', 'h', 'l', 'o')
解析:【喵呜刷题小喵解析】:题目中问的是`set('hello')`的运行结果。在Python中,`set()`是一个将输入的可迭代对象转换为集合的函数。集合中的元素是无序的,并且集合中的元素是不重复的。因此,`set('hello')`的运行结果是一个包含`h`、`e`、`l`和`o`这四个元素的集合,但是元素的顺序是不确定的。所以,正确答案应该是C选项,即`{'e', 'h', 'l', 'o'}`,而不是A、B或D选项。
14、print(sum([5,10,min(7,4,6)]))的运行结果是?( )
A、22
B、21
C、4
D、19
解析:【喵呜刷题小喵解析】首先,根据Python的运算优先级,min函数会先执行。min(7,4,6)的结果是4。接着,求和函数sum会对列表中的每一个元素求和,所以,sum([5,10,4])的结果是5+10+4=19。因此,print(sum([5,10,min(7,4,6)]))的运行结果是19。所以答案是D选项,19。
15、divmod(100,3)的执行结果是?( )
A、(1, 33)
B、(33, 1)
C、[33,1]
D、[1,33]
解析:【喵呜刷题小喵解析】在Python中,`divmod()`函数返回两个值,第一个值是除法的商,第二个值是除法的余数。对于`divmod(100,3)`,商是33,余数是1,所以返回的结果是`(33, 1)`,即选项B。
16、下列表达式结果是False的是?( )
A、all({})
B、all([10])
C、all(['1','2','3',''])
D、all(['1','2','3'])
解析:【喵呜刷题小喵解析】首先,我们要理解题目中提到的“all”函数的作用。一般来说,“all”函数会对其内部的序列中的每一个元素进行测试,只有当所有元素都满足某个条件时,函数才会返回True,否则返回False。对于选项A,`all({})`,这里是一个空列表,因为没有任何元素,所以“all”函数会返回True,因为没有任何元素不满足条件。对于选项B,`all([10])`,这里只有一个元素10,显然10满足“all”函数的条件,所以函数会返回True。对于选项D,`all(['1','2','3'])`,这里有三个字符串元素,都是非空字符串,都满足“all”函数的条件,所以函数会返回True。对于选项C,`all(['1','2','3',''])`,这里有一个空字符串元素,显然空字符串不满足“all”函数的条件,所以函数会返回False。因此,答案是C。
17、将字符串或数字转换为浮点数的函数是?( )
A、chr()
B、float()
C、int()
D、str()
解析:【喵呜刷题小喵解析】:在Python中,将字符串或数字转换为浮点数的函数是`float()`。`chr()`函数用于返回指定整数的字符,`int()`函数用于将字符串或数字转换为整数,`str()`函数用于将对象转换为字符串。因此,正确答案是B。
18、以下表达式的值为True是?( )
A、bool(2022)
B、bool(0)
C、bool()
D、bool({})
解析:【喵呜刷题小喵解析】:在Python中,`bool()`函数用于将给定的参数转换为布尔值。对于非零的数字,`bool()`会返回`True`。因此,`bool(2022)`的值为`True`。而`bool(0)`的值为`False`,因为0在布尔上下文中被视为`False`。`bool()`函数不接受空括号作为参数,所以`bool()`单独调用会引发一个`TypeError`异常。同样地,`{}`不是一个合法的数字或字符串,因此`bool({})`也会引发一个`TypeError`异常。所以,正确的答案是选项A。
19、有这样一段程序: a=[“香蕉“,”苹果”,”草莓”,“哈密瓜”] fs=open(“fruits.csv”,”w”) fs.write(“,”.join(a)+‘\n’) fs.close() 该段程序执行后,该csv文件中的内容是?( )
A、香蕉 苹果 草莓 哈密瓜
B、香蕉,苹果,草莓,哈密瓜
C、香蕉苹果草莓哈密瓜
D、["香蕉","苹果","草莓","哈密瓜"]
解析:【喵呜刷题小喵解析】在给出的程序中,列表a的内容为["香蕉","苹果","草莓","哈密瓜"]。然后使用join方法将列表中的元素以逗号连接成一个字符串"香蕉,苹果,草莓,哈密瓜"。接着,使用write方法将这个字符串写入到"fruits.csv"文件中,并在字符串后添加了一个换行符'\n'。因此,执行该程序后,csv文件中的内容为"香蕉,苹果,草莓,哈密瓜",与选项B一致。
20、关于文件的读写操作,下列说法不正确的是?( )
A、read( )函数读取文件内容后,生成的是一个字符串 。
B、readline( )每次只读取文件中的一行,并返回字符串类型数据。
C、readlines( )函数每次按行读取整个文件的内容,并返回list类型数据。
D、读取文件内容只能用reader( )对象。
解析:【喵呜刷题小喵解析】:在Python中,文件读取操作有多种方式。A选项提到的`read()`函数确实用于读取文件内容,并返回一个字符串。B选项的`readline()`函数每次只读取文件中的一行,并返回字符串类型数据。C选项的`readlines()`函数每次按行读取整个文件的内容,并返回一个包含所有行的列表。然而,D选项中的`reader()`并不是Python的标准文件读取函数。实际上,`reader()`并不是Python内置的文件读取方法,因此D选项的说法是不正确的。
21、关于下列列表,说法正确的是?( ) s=[ [“佩奇”,“100”,“86”,“85”,“90”], [“苏西”,“78”,“88”,“98”,“89”], [“佩德罗”,“80”,“66”,“80”,“92”]]
A、这是一组二维数据
B、这样的数据不能存储到CSV文件中
C、无法读取[“佩奇”,“100”,“86”,“85”,“90”]这条数据
D、必须手动写入到CSV文件中
解析:【喵呜刷题小喵解析】:首先,我们来分析题目中的列表s。列表s是一个二维列表,其中每个子列表都包含了一个学生的名字和四个成绩。这样的数据结构可以看作是一个二维数据。接下来,我们逐一分析选项:A. 这是一组二维数据。这与我们的分析相符,因为列表s确实是一个二维数据结构。B. 这样的数据不能存储到CSV文件中。这是错误的。CSV文件是一种常见的数据存储格式,可以存储二维数据。C. 无法读取[“佩奇”,“100”,“86”,“85”,“90”]这条数据。这同样是不正确的。从列表中我们可以看到,这是一个格式正确的数据。D. 必须手动写入到CSV文件中。这也是不正确的。虽然手动写入到CSV文件是可行的,但CSV文件也支持通过编程方式写入。因此,根据以上分析,我们可以得出结论:正确答案是A,即这是一组二维数据。
22、有关于write()函数的说法正确的是?( )
A、write( )函数只能向文件中写入一行数据
B、write( )函数的参数不是字符串类型
C、write( )函数也可以向文件中写入多行数据
D、write( )函数和writelines( )函数完全相同
解析:【喵呜刷题小喵解析】在Python中,write()函数通常用于向文件写入字符串数据,并且写入的数据量并不仅仅局限于一行,而是可以写入任意数量的数据,因此C选项是正确的。而A选项中的描述是不准确的,write()函数可以写入任意数量的数据,而不仅仅是一行。B选项也是错误的,write()函数的参数通常是字符串类型。D选项也是错误的,write()函数和writelines()函数虽然都是用于写入文件,但它们的用法和参数是不同的,因此它们并不是完全相同的。
23、对于在csv文件中追加数据,下列说法正确的是?( )
A、只能以单行方式追加数据
B、只能以多行方式追加数据
C、多行数据追加的函数是writerow( )
D、以单行方式或多行方式追加都可以
解析:【喵呜刷题小喵解析】:在Python中,使用csv模块向CSV文件中追加数据时,既可以以单行方式追加数据,也可以使用多行数据一次性追加。对于单行追加,可以使用writerow()方法,而对于多行数据追加,可以在一个循环中多次调用writerow()方法,或者在调用writerow()方法之前先将多行数据存储在列表等数据结构中,再一次性写入。因此,D选项“以单行方式或多行方式追加都可以”是正确的说法。A、B选项的表述都过于片面,而C选项的表述不准确,因为writerow()方法只能用于单行数据追加,而不是多行数据追加。
24、Python的异常处理try....except...else...finally机制中,以下哪部分语句一定能得到全部执行?( )
A、try子句
B、except子句
C、else子句
D、finally子句
解析:【喵呜刷题小喵解析】:在Python的异常处理机制中,`try`、`except`、`else`和`finally`各部分有不同的作用和执行时机。* `try`子句:包含可能引发异常的代码。* `except`子句:处理`try`子句中引发的异常。* `else`子句:如果`try`子句中的代码没有引发异常,`else`子句中的代码会被执行。* `finally`子句:无论`try`子句中的代码是否引发异常,`finally`子句中的代码都会被执行。因此,`finally`子句一定能得到全部执行。
25、Python的异常处理机制中,以下表述哪项是错误的?( )
A、如果当try中的语句执行时发生异常,Python就执行匹配该异常的except子句。
B、如果当try中的语句执行时发生异常,try代码块的剩余语句将不会被执行。
C、如果在try子句执行时没有发生异常,Python将执行else语句后的语句。
D、异常处理结构能够发现程序段中的语法错误。
解析:【喵呜刷题小喵解析】:在Python的异常处理机制中,A选项描述正确,当try中的语句执行时发生异常,Python会执行匹配该异常的except子句。B选项描述也正确,当try中的语句执行时发生异常,try代码块的剩余语句将不会被执行。C选项描述同样正确,如果在try子句执行时没有发生异常,Python将执行else语句后的语句。而D选项描述错误,异常处理结构不能发现程序段中的语法错误,它只能处理运行时发生的异常。因此,D选项是错误的。
二、判断题
26、二进制数转化为十进制数的方法是:按权展开、逐项相加,如:(101)2=(10)10。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:题目中的说法有误。二进制数转化为十进制数的方法是:按权展开、逐项相加。但题目中给出的例子(101)2=(10)10是错误的。实际上,(101)2=(5)10。因此,题目的说法是错误的,答案应选B。
27、语句print(round(2.785, 2))运行后的结果是2.79。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`round()`函数用于对浮点数进行四舍五入。`round(2.785, 2)`表示将2.785四舍五入到小数点后两位,结果为2.79。因此,语句`print(round(2.785, 2))`运行后的结果是2.79,所以答案是正确的。
28、map() 不会根据提供的函数对指定序列做映射。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`map()`函数用于根据提供的函数对指定序列做映射。它会将函数应用于序列中的每个元素,并返回一个新的迭代器,其中包含应用函数后的结果。因此,题目中的说法“map()不会根据提供的函数对指定序列做映射”是错误的。所以,答案应选择B,即错误。
29、语句print(tuple(range(5)))的输出结果是(0, 1, 2, 3, 4)。( )
A 正确
B 错误
解析:【喵呜刷题小u解析】:`range(5)`生成的是一个0到4的整数序列,即[0, 1, 2, 3, 4]。使用`tuple()`函数将这个列表转化为元组后,输出结果为`(0, 1, 2, 3, 4)`。所以题目中的说法是错误的,正确答案应为B。
30、运行语句set('2022'),其输出结果是{'2','0','2','2'} ( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`set()`函数用于创建一个集合。当运行`set('2022')`时,它会将字符串'2022'中的每个字符作为一个独立的元素添加到集合中,所以输出的集合应该是{'2', '0', '2', '2'}。但题目中给出的输出结果是{'2','0','2','2'},这样的表示方式实际上与集合的原始表示方式是一样的,只是重复的元素在集合中只会出现一次。因此,题目的表述存在误导性,正确答案应为B。
31、f=open(‘ss.csv’,’r’) n=f.read().strip(“\n”).split(“,”) f.close() 这段代码的功能是读取文件中的数据到列表。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:这段代码的功能是读取文件中的数据到列表。首先,使用`open`函数以只读模式('r')打开名为'ss.csv'的文件,并将文件对象赋值给变量`f`。然后,使用`f.read()`读取文件的所有内容,使用`strip("\n")`去除字符串末尾的换行符,再使用`split(",")`将字符串按照逗号分隔,得到一个列表。最后,使用`f.close()`关闭文件。因此,这段代码的功能是读取文件中的数据到列表,所以答案是A。
32、一维数组可以用列表实现,二维数组则不能用列表实现。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,一维数组可以用列表实现,二维数组同样也可以用列表实现。例如,二维数组可以表示为一个列表的列表。所以,题目的说法是错误的。
33、用with open (‘fruits.csv’,’r’)as f 语句,打开fruits.csv文件,在处理结束后不会自动关闭被打开的文件,因此需要写上f.close( )语句。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,使用`with`语句打开文件时,会在代码块执行完毕后自动关闭文件,无需显式调用`f.close()`。因此,题目中的说法是错误的。所以答案选择B。
34、异常处理结构中,finally程序段中的语句不一定都会得到执行。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在异常处理结构中,finally程序段中的语句一定会得到执行,无论是否发生异常。因此,本题中给出的判断“finally程序段中的语句不一定都会得到执行”是错误的。
35、在计算机中,每一个二进制位可以表示0和1两种信息。( )
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在计算机中,每一个二进制位(bit)只能表示0和1两种信息。二进制位是计算机存储和运算的基础,也是构成计算机所有数据的最小单位。每个二进制位只有两种状态,即0和1,因此题目中的说法是正确的。
三、编程题
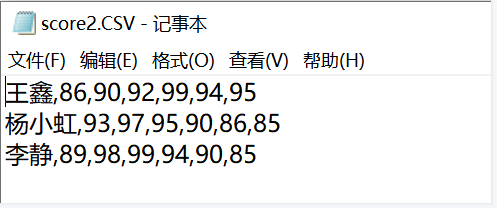
36、36.下面程序实现对二维数据的处理,请你补全代码。
f=open('/data/score2.csv','r')
a=[]
for i in f:
a.append(i.strip().split(','))
f.close()
①
for i in a:
s=''
for j in i:
②
print(s)
程序执行结果为:
[['王鑫', '86', '90', '92', '99', '94', '95'], ['杨小虹', '93', '97', '95', '90', '86', '85'], ['李静', '89', '98', '99', '94', '90', '85']]
王鑫 86 90 92 99 94 95
杨小虹 93 97 95 90 86 85
李静 89 98 99 94 90 85
参考答案:
略
解析:【喵呜刷题小喵解析】:根据题目描述,我们需要补全代码以实现对二维数据的处理。根据给定的程序执行结果,我们可以推测出原始代码中的①和②部分应该完成的功能。在①部分,我们假设原始代码已经读取了二维数据到列表a中,现在需要遍历这个列表。根据题目描述,我们需要在遍历列表a的过程中,对每一行数据进行处理。在②部分,我们需要将每一行的数据拼接成一个字符串,并在每个数据之间加上一个空格。根据题目描述,我们需要在遍历列表i的过程中,将每个元素j添加到字符串s中,并在每个元素之间加上一个空格。因此,我们可以将①和②部分的代码补全为:```pythonfor i in a:s=''for j in i:s+=j+' 'print(s)```这段代码将遍历列表a中的每一行数据,将每一行的数据拼接成一个字符串,并在每个数据之间加上一个空格,然后将这个字符串打印出来。
37、37.在三位数的自然数中,找出至少有一位数字是5的,至少能被3整除的所有整数,并统计个数,具体代码如下:
count=0
lst=[]
for i in range( ① ):
if i%3==0:
a=i%10
b=i//10%10
c= ②
if ③ :
count+=1
lst.append(i)
print("这样的三位数有:",lst)
print("总数量有:",count)
参考答案:
略
解析:【喵呜刷题小喵解析】:本题要求找出三位数中至少有一位数字是5,并且至少能被3整除的所有整数。1. 初始化变量count为0,lst为空列表。2. 使用for循环遍历三位数的范围,即100到999。3. 在循环中,首先判断i是否能被3整除,即i % 3 == 0。4. 如果i能被3整除,则分别提取i的个位、十位和百位数字,分别赋值给变量a、b和c。5. 判断a、b、c中是否有至少一个数字是5,即a == 5 or b == 5 or c == 5。6. 如果满足条件,则将i加入到lst列表中,并将count加1。7. 最后输出lst列表和count的值。根据上述思路,填写①、②和③处的代码即可。其中①处填写的范围应为100到999,②处填写的表达式应为i // 100,③处填写的条件应为a == 5 or b == 5 or c == 5。
38、38.输入一个正数,以下代码编程求出它的平方根。请你补全代码。

参考答案:
略
解析:【喵呜刷题小喵解析】首先,我们需要导入Python的math模块,该模块提供了许多数学函数,包括平方根函数sqrt()。然后,我们使用input()函数从用户那里获取一个正数,并将其转换为浮点数类型。接着,我们使用math.sqrt()函数计算该数的平方根,并将结果存储在变量sqrt_num中。最后,我们使用print()函数输出该数的平方根。注意,由于用户输入的数据可能不是正数,因此在计算平方根之前,我们需要进行验证。在本题中,我们假设用户输入的是正数,因此没有进行验证。在实际编程中,我们需要根据具体需求进行验证。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




