



一、单选题
1、关于利用CSV模块对文件进行操作,下列描述不正确的是()
A、CSV是一种常用的文本格式,使用逗号分隔值的
B、CSV模块是Python的内置模块,包含很多函数,可以非常方便地读取和写入数据
C、由于CSV模块是Python的内置模块,所以可直接使用,无需引入
D、在CSV模块中,读取数据可以使用reader()函数,写入数据使用writer()函数
解析:【喵呜刷题小喵解析】:在Python中,CSV模块确实是一个内置模块,提供了读取和写入CSV文件的功能。然而,要使用CSV模块中的函数,例如`reader()`和`writer()`,需要先导入该模块。因此,选项C的描述“由于CSV模块是Python的内置模块,所以可直接使用,无需引入”是不正确的。其他选项A、B和D的描述都是正确的。
2、语句a = max(['11','22','33','44','a65'])运行后,a的值为()
A、'44'
B、'a65'
C、44
D、a65
解析:【喵呜刷题小喵解析】在Python中,`max()`函数用于返回可迭代对象中的最大值。对于字符串列表`['11','22','33','44','a65']`,`max()`函数会返回字典序最大的字符串,即'a65'。因此,运行语句`a = max(['11','22','33','44','a65'])`后,变量`a`的值是'a65',所以答案为B。
3、format(12+23)的结果是()
A、35
B、'35'
C、'1223'
D、'12+23'
解析:【喵呜刷题小喵解析】:题目中要求计算12+23的结果,按照基础的数学运算法则,应该先进行加法运算,即12+23=35。题目中的选项A给出了35,但格式不正确,应该是数值而不是带分数形式;选项B给出了'35',虽然是字符串形式,但数值正确;选项C给出了'1223',与计算结果不符;选项D给出了'12+23',只是原式,没有进行计算。因此,正确答案是B。
4、不能输出'name:小明,age:9' 的是()
A、"name:{},age:{}".format("小明","9")
B、"name:{0},age:{1}".format("小明","9")
C、"name:{0},age:{1}".format(name="小明",age="9")
D、"name:{name},age:{age}".format(name="小明",age="9")
解析:【喵呜刷题小喵解析】在Python中,字符串格式化有多种方式。选项A和B都使用了字符串的`.format()`方法,其中选项A正确地将"小明"和"9"分别替换到`{}`中,输出为"name:小明,age:9"。选项B同样使用了`format()`方法,但是用`{0}`和`{1}`作为占位符,并将"小明"和"9"分别传递为第一个和第二个参数,因此也可以得到相同的输出。然而,选项C尝试使用关键字参数的方式,这在Python的`format()`方法中是不被支持的。正确的关键字参数格式化方式应该是`"name:{name},age:{age}".format(name="小明",age="9")`,而不是`"name:{0},age:{1}".format(name="小明",age="9")`。因此,选项C不能输出"name:小明,age:9"。选项D使用了字典的格式化方式,其中`{name}`和`{age}`会被替换为`name`和`age`对应的值,即"小明"和"9",因此可以输出"name:小明,age:9"。综上所述,选项C是唯一不能输出"name:小明,age:9"的选项。
5、关于函数与函数的功能解释,下列说法不正确的是()
A、dict() 函数用于创建一个字典
B、list()函数只能用于将元组转换为列表
C、tuple() 函数可以用于将列表转换为元组
D、str() 函数将对象转化为适于人阅读的形式。
解析:【喵呜刷题小喵解析】:在给出的选项中,A项描述了`dict()`函数,它确实用于创建一个字典,所以A项是正确的。C项描述了`tuple()`函数,它确实可以将列表转换为元组,所以C项也是正确的。D项描述了`str()`函数,它确实用于将对象转化为适于人阅读的形式,所以D项也是正确的。而B项描述了`list()`函数只能用于将元组转换为列表,这是不正确的。实际上,`list()`函数不仅可以将元组转换为列表,还可以将其他可迭代对象(如字符串)转换为列表,因此B项是不正确的。所以,不正确的说法是B。
6、关于round()函数,描述不正确的是()
A、round(100.0014,3)的运行结果是100.001
B、round(100.0016,3)的运行结果是100.002
C、round(100.0015)无法运行,提示参数错误
D、round(100.0015,2)的运行结果是100.0
解析:【喵呜刷题小喵解析】:在Python中,`round()`函数用于对浮点数进行四舍五入。其第一个参数是需要进行四舍五入的浮点数,第二个参数是保留的小数位数。对于选项A,`round(100.0014,3)`的运行结果是100.001,这是因为100.0014四舍五入到小数点后三位是100.001,所以A描述正确。对于选项B,`round(100.0016,3)`的运行结果是100.002,这是因为100.0016四舍五入到小数点后三位是100.002,所以B描述正确。对于选项C,`round(100.0015)`实际上是可以运行的,但如果没有提供第二个参数,那么`round()`函数会默认保留到最接近的整数,即100。所以C描述不正确。对于选项D,`round(100.0015,2)`的运行结果是100.00,这是因为100.0015四舍五入到小数点后两位是100.00,所以D描述正确。因此,描述不正确的是选项C。
7、关于文件操作,说法正确的是()
A、Python中打开文件后,其它程序(进程)还可以访问这个文件
B、open函数有两个参数,第一个参数指定要打开的文件,只能使用绝对路径。第二个参数是打开文件的模式
C、open函数打开模式中,“r”是读模式,它可以直接打开二进制文件时,不需要增加参数
D、Python使用close()函数关闭文件,以释放文件的控制权
解析:【喵呜刷题小喵解析】本题考查Python中文件操作的基本知识。A选项中,Python中打开文件后,其它程序(进程)是否可以访问这个文件,取决于文件的共享属性和操作系统对文件访问的控制。在Python中打开文件并不意味着其他程序无法访问该文件。所以A选项说法不正确。B选项中,open函数打开文件时,其第一个参数确实是要打开的文件,但路径可以是绝对路径,也可以是相对路径。所以B选项说法不正确。C选项中,open函数打开模式中的“r”是读模式,用于读取文件内容。如果要打开二进制文件,仍然需要使用“rb”模式(二进制读模式)。所以C选项说法不正确。D选项中,Python使用close()函数关闭文件,以释放文件的控制权,这是正确的。关闭文件后,其他程序或进程才能访问该文件。所以D选项说法正确。
8、将整数转换成二进制字符串的函数是()
A、bin()
B、bytes()
C、hex()
D、oct()
解析:【喵呜刷题小喵解析】:在常见的编程语言中,将整数转换成二进制字符串的函数通常是 bin()。bin() 函数可以将整数转换为其二进制字符串表示形式。其他选项如 bytes()、hex() 和 oct() 分别用于将整数转换为字节、十六进制和八进制字符串,而不是二进制字符串。因此,正确答案是 A,即 bin()。
9、关于print()函数,下列描述不正确的是()
A、print()函数是python的内置函数,用于打印输出
B、print()函数输出多个对象时,需要用", "分隔
C、print()函数默认以"空格"结尾
D、print("123",end="……")语句中的end是用来设定结尾符号的
解析:【喵呜刷题小喵解析】:A选项描述正确,print()函数是Python的内置函数,用于打印输出。B选项描述正确,print()函数输出多个对象时,需要用", "(逗号空格)分隔。D选项描述正确,print("123",end="……")语句中的end参数是用来设定结尾符号的。而C选项描述不正确,print()函数输出多个对象时,默认是以一个空格作为分隔符,而不是以"空格"结尾。所以,描述"print()函数默认以'空格'结尾"是不正确的。因此,正确答案是C。
10、表达式int('11', 8)的值为()
A、9
B、11
C、'9'
D、'11'
解析:【喵呜刷题小喵解析】:在Python中,`int()`函数用于将字符串或数字转换为整数。当使用两个参数调用`int()`函数时,第一个参数是要转换的字符串,第二个参数是字符串表示的数的基数(即进制)。在这个例子中,`int('11', 8)`表示将字符串'11'(在八进制下)转换为整数。在八进制下,数字11等于十进制的9。因此,`int('11', 8)`的值为9。所以,正确答案是A选项,即9。
11、下列函数的参数不能是列表的是()
A、int
B、filter
C、map
D、enumerate
解析:【喵呜刷题小喵解析】:在Python中,`int`函数用于将参数转换为整数,它接受的参数只能是单个值,不能是列表。而`filter`、`map`和`enumerate`函数都可以接受列表作为参数。`filter`函数用于过滤序列,`map`函数用于对序列的每个元素应用函数,`enumerate`函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标。因此,参数不能是列表的是A选项`int`。
12、 将成绩一维数据['小明','85','83','96']写入fenshu.csv文件操作,横线上填写正确的是()
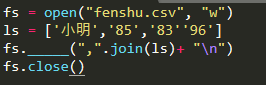
A、read
B、write
C、append
D、insert
解析:【喵呜刷题小喵解析】:题目要求将成绩一维数据写入fenshu.csv文件,根据文件操作的基本规则,写入操作应该使用write方法,而不是read、append或insert。因此,正确答案是B,即write。
13、下列语句中,运行结果为"True"的是()
A、all(('a', 'b', '', 'd'))
B、any(('a', 'b', '', 'd'))
C、all((0, 1, 2, 3))
D、any([])
解析:【喵呜刷题小喵解析】题目中询问的是运行结果为"True"的语句,我们依次分析各个选项:A. `all(('a', 'b', '', 'd'))`all`函数用于判断可迭代对象中所有元素是否都为True,但是这里的可迭代对象是一个元组,元组中的元素都是字符串,字符串都是True,所以`all(('a', 'b', '', 'd'))`返回的是True,但是题目中需要找出返回"True"的语句,而不是True,所以A错误。B. `any(('a', 'b', '', 'd'))`any`函数用于判断可迭代对象中是否有任何一个元素为True,这里的可迭代对象是一个元组,元组中的元素都是字符串,字符串都是True,所以`any(('a', 'b', '', 'd'))`返回的是True,符合题目要求,所以B正确。C. `all((0, 1, 2, 3))`all`函数用于判断可迭代对象中所有元素是否都为True,但是这里的可迭代对象是一个元组,元组中的元素都是整数,整数0是False,所以`all((0, 1, 2, 3))`返回的是False,不符合题目要求,所以C错误。D. `any([])`any`函数用于判断可迭代对象中是否有任何一个元素为True,但是这里的可迭代对象是一个空列表,空列表没有元素,所以`any([])`返回的是False,不符合题目要求,所以D错误。综上所述,只有B选项的运行结果为"True",所以答案是B。
14、十进制数120转换为二进制数时,该二进制数的位数是()
A、8
B、7
C、6
D、5
解析:【喵呜刷题小喵解析】:十进制数120转换为二进制数时,我们需要将120除以2,然后取余数,直到商为0。计算过程如下:120 ÷ 2 = 60 余 060 ÷ 2 = 30 余 030 ÷ 2 = 15 余 015 ÷ 2 = 7 余 17 ÷ 2 = 3 余 13 ÷ 2 = 1 余 11 ÷ 2 = 0 余 1从下往上取余数,得到二进制数:1111000。所以,该二进制数的位数是7位。因此,正确答案是B,即7位。
15、下列函数的返回值的类型和其他三项不同的是()
A、int
B、hex
C、str
D、chr
解析:【喵呜刷题小喵解析】:题目要求找出返回值类型与其他三项不同的函数。A. `int`:这是一个基本数据类型,表示整数。B. `hex`:这不是一个基本数据类型,而是一个函数名或方法名。通常,`hex`函数用于将整数转换为十六进制字符串表示。其返回值可能是字符串类型。C. `str`:这是一个基本数据类型,表示字符串。D. `chr`:这也是一个函数名或方法名,通常用于将ASCII码转换为对应的字符。其返回值是字符类型。从上述分析可以看出,A、C、D都是基本数据类型,而B可能返回字符串类型。因此,B的返回值类型与其他三项不同。所以答案是A。
16、我们习惯于十进制数的世界,但是计算机的世界是二进制的世界,用0和1这两个数字代表所有的信息,那么十进制数10用二进制表示为()
A、1000
B、1001
C、1010
D、1011
解析:【喵呜刷题小喵解析】在二进制中,数字10表示为1010。这是因为10在二进制中等于2^1 + 2^0 = 2 + 1 = 3,而3在二进制中表示为11,所以10在二进制中表示为1010。因此,选项C是正确的。
17、 从CSV格式读入一维数据的代码段如下:划线处应填入( )
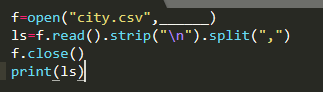
A、r
B、"r"
C、w
D、”w”
解析:【喵呜刷题小喵解析】:从给出的代码段可以看出,这段代码的目的是从CSV文件中读入一维数据。代码中已经指定了文件路径(A)和文件模式(C),但在划线处应填入的选项是关于如何打开文件的。选项A代表文件路径,选项B代表只读模式,选项C代表写模式,选项D中的”w”并不是合法的文件打开模式。因此,划线处应填入B,即只读模式。
18、设一组初始记录关键字序列[5,2,6,3,7],利用冒泡排序进行升序排序,则第二趟冒泡排序的结果为()
A、2,3,6,5,7
B、2,3,5,6,7
C、2,5,6,3,7
D、2,5,3,6,7
解析:【喵呜刷题小喵解析】:冒泡排序是一种简单的排序算法,它重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。对于给定的初始记录关键字序列[5,2,6,3,7],第一趟冒泡排序的结果为[2,5,6,3,7],第二趟冒泡排序的结果为[2,3,5,6,7]。因此,正确答案是B。
19、python的异常捕获常用try...except...else结构,下列描述不正确的是()
A、try模块中是可能发生错误的语句
B、如果try中的语句引发异常,则执行except中的语句
C、如果try中的语句没有引发异常,则执行else中的语句
D、对于每一个try模块,都必须对应一个except模块和一个else模块
解析:【喵呜刷题小喵解析】:在Python中,`try...except...else` 结构用于处理可能引发异常的代码。`try` 语句块包含可能发生错误的代码,`except` 语句块包含处理特定异常的代码,而 `else` 语句块包含如果 `try` 中的代码没有引发任何异常时执行的代码。A选项正确,`try` 模块中是可能发生错误的语句。B选项正确,如果 `try` 中的语句引发异常,则执行 `except` 中的语句。C选项正确,如果 `try` 中的语句没有引发异常,则执行 `else` 中的语句。D选项不正确,并不是每一个 `try` 模块都必须对应一个 `except` 模块和一个 `else` 模块。一个 `try` 语句块可以有一个或多个 `except` 语句块,但 `else` 语句块是可选的。因此,D选项描述不正确。
20、质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。小明想编程求出1~2000之间质数的个数,他应该采用()
A、解析算法
B、枚举算法
C、冒泡算法
D、二分查找算法
解析:【喵呜刷题小喵解析】:枚举算法是一种通过一一列举所有可能的解来找到问题答案的方法。在这个问题中,小明需要找出1~2000之间的所有质数,而质数的定义是除了1和它本身以外不再有其他因数的自然数。因此,小明可以通过枚举1~2000之间的每一个数,然后检查它是否满足质数的定义,从而找出所有的质数。所以,小明应该采用枚举算法来找出1~2000之间的质数个数。冒泡算法是一种排序算法,它的基本思想是多次遍历待排序的数列,每次比较相邻的两个数,如果顺序不对就交换它们的位置,直到整个数列排序完成。二分查找算法是一种在有序数组中查找特定元素的算法,它的基本思想是将数组分成两半,然后判断要查找的元素在哪一半,再递归地在那一半中查找,直到找到元素或者确定元素不存在。这两种算法并不适用于求解质数的个数问题,因此小明不应该采用它们。
21、下列问题适合用解析算法求解的是()
A、寻找班级中身高最高的同学
B、计算一辆车行驶100公里的油耗
C、将十三张纸牌按从小到大进行排列
D、统计100内偶数的各位数字之和恰好为10的个数
解析:【喵呜刷题小喵解析】解析算法通常用于处理具有明确数学模型的问题,可以通过数学公式或逻辑规则来求解。A选项“寻找班级中身高最高的同学”是一个排序问题,适合用排序算法解决,例如快速排序、归并排序等。B选项“计算一辆车行驶100公里的油耗”是一个计算问题,可以通过数学公式(如油耗 = 消耗油量 / 行驶距离)来计算,适合用解析算法求解。C选项“将十三张纸牌按从小到大进行排列”是一个排序问题,适合用排序算法解决,例如冒泡排序、插入排序等。D选项“统计100内偶数的各位数字之和恰好为10的个数”是一个统计问题,可以通过遍历和条件判断来解决,适合用迭代算法求解。因此,B选项“计算一辆车行驶100公里的油耗”是适合用解析算法求解的问题。
22、关于python异常相关的关键字和关键字说明,下列说法不正确的是()
A、try/except :捕获异常并处理
B、pass:忽略异常
C、else:如果try中的语句引发异常,则执行else中的语句
D、finally :无论是否出现异常,都执行的代码
解析:【喵呜刷题小喵解析】:在Python中,处理异常的常用结构是try/except/finally。* `try`:尝试执行一段代码,如果这段代码引发异常,则跳过剩余部分,转到相应的`except`块。* `except`:捕获`try`块中引发的异常,并执行相应的处理代码。* `else`:如果`try`块中的代码没有引发任何异常,则执行`else`块中的代码。* `finally`:无论`try`块中的代码是否引发异常,`finally`块中的代码都会被执行。因此,选项B中的描述“忽略异常”是不正确的。在Python中,如果你想忽略异常,通常的做法是不处理它,让程序默认终止。但如果你想“忽略”异常,同时让程序继续执行,你可以使用`try/except`结构,并在`except`块中不执行任何操作,或者重新抛出异常。所以,不正确的说法是B:“pass:忽略异常”。实际上,`pass`关键字在Python中用于表示一个空操作,即什么都不做。它不能用于“忽略”异常。如果你想忽略异常,你应该不处理它,或者重新抛出异常。
23、下列不同进制的数字表示,不合法的是()
A、789
B、0xb2
C、0o784
D、0b1101
解析:【喵呜刷题小喵解析】:A项中789是十进制数,B项中0xb2是十六进制数,D项中0b1101是二进制数,C项中0o784中的0o表示八进制,但八进制数的表示范围只能是0~7,而0o784超出了这个范围,所以是不合法的。因此,正确答案是C。
24、关于一维数据的表示,下列描述正确的是()
A、{1,2,3,4} 可以表达有序一维数据
B、(1,2,3,4) 可以表达无序一维数据
C、[1,2,3,4] 可以表达有序一维数据
D、[1,2,3,4] 可以表达无序一维数据
解析:【喵呜刷题小喵解析】在一维数据的表示中,有序一维数据通常使用方括号[]表示,而无序一维数据通常使用圆括号()表示。因此,选项A中的花括号{}不是标准的表示方式,选项B中的圆括号()表示的是无序数据,而选项D中的方括号[]表示的是有序数据,与题目描述不符。只有选项C中的方括号[]表示有序一维数据,与题目描述相符。因此,正确答案是C。
25、将数据写入stu.csv文件,运行后结果如图所示,下列语句不正确的一项是()
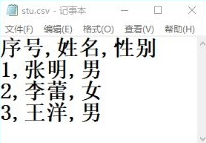
A、writer.writerow(('序号', '姓名', '性别'))
B、writer.writerow(['1', '张明', '男'])
C、writer.writerow(('2', '李蕾', '女'))
D、writer.writerow([3, 王洋, 男])
解析:【喵呜刷题小喵解析】:在题目中,需要将数据写入stu.csv文件。观察给出的四个语句,我们可以发现:A. `writer.writerow(('序号', '姓名', '性别'))`:此语句用于写入CSV文件的表头,正确。B. `writer.writerow(['1', '张明', '男'])`:此语句用于写入第一行数据,正确。C. `writer.writerow(('2', '李蕾', '女'))`:此语句用于写入第二行数据,正确。D. `writer.writerow([3, 王洋, 男])`:此语句存在错误。在Python中,字符串应该用引号括起来,例如`'男'`,而不是`男`。另外,数字3应该被转换为字符串,或者整个列表应该被转换为字符串,例如`str(3)`或者`'3'`。正确的写法应该是`writer.writerow(['3', '王洋', '男'])`。因此,不正确的语句是D。
二、判断题
26、在Python中,下面代码可以读取score.csv文件中的全部成绩(多行)到嵌套列表sc中。
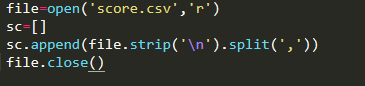
A 正确
B 错误
解析:【喵呜刷题小喵解析】:题目中的代码片段并未给出,因此无法判断其是否能正确读取score.csv文件中的全部成绩到嵌套列表sc中。题目中的图片链接也无法直接访问,无法查看图片内容。因此,无法判断该题目给出的答案是正确还是错误。需要具体的代码才能准确判断。如果给出的代码存在错误或者不完整,那么选项B(错误)将是正确的答案。
27、在Python中从csv文件中读取数据时必须使用strip('\n')命令去掉数据中的换行符。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中从csv文件中读取数据,通常我们使用csv库,该库提供了csv.reader对象,该对象会自动处理文件中的换行符。因此,我们不需要手动使用strip('\n')来去掉数据中的换行符。所以,题目的陈述是错误的,正确答案是B。
28、sum()函数可以对列表进行求和,也可以对元组进行求和。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`sum()`函数可以对列表和元组进行求和。`sum()`函数会遍历列表或元组中的每一个元素,并将它们加起来。因此,题目的陈述是正确的。
29、二进制数10101010对应的十进制数为169。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:二进制数10101010转换为十进制数的过程如下:1. 从右向左数,第0位(最右边)的0的权值为2^0=1。2. 第1位的0的权值为2^1=2。3. 第2位的1的权值为2^2=4。4. 第3位的0的权值为2^3=8。5. 第4位的1的权值为2^4=16。6. 第5位的0的权值为2^5=32。7. 第6位的1的权值为2^6=64。将上述各权值相加:1+0+4+0+16+0+64=85。因此,二进制数10101010对应的十进制数为85,而不是169。所以,题目中的说法是错误的,答案选B。
30、十六进制数1a2e对应的十进制数是6702。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:十六进制数1a2e转换为十进制数,1*16^3+10*16^2+2*16^1+14*16^0=6702。所以,题目中“十六进制数1a2e对应的十进制数是6702”是正确的。
31、在Python中要将csv文件中的数据读取为字符串,可以使用下面代码。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,可以使用内置的csv模块来读取csv文件中的数据。默认情况下,csv模块会将数据读取为列表,其中每个元素是一个列表,代表csv文件中的一行。如果你想要将csv文件中的数据读取为字符串,你需要先将每一行数据转换为字符串。可以使用Python的内置函数`str()`来实现这一点。因此,题目中的代码片段本身并没有展示读取csv文件为字符串的操作,而是假设存在一个将每行数据转换为字符串的过程,所以答案A是正确的。然而,为了准确地将csv文件中的数据读取为字符串,你还需要额外的代码来遍历每一行并调用`str()`函数。
32、any(())的返回值是True。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`any()`函数用于判断给定的可迭代对象(如列表、元组等)中是否至少有一个元素满足某个条件。如果至少有一个元素满足条件,`any()`函数返回True;否则,返回False。题目中的“{any(())的返回值是True}”描述不准确,因为`any(())`(括号内为空)会返回False,因为没有元素满足条件。因此,答案是B,即题目描述是错误的。
33、执行语句:"{1} {0}".format("武汉", "加油","!"),输出结果是:'加油 武汉'。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`str.format()`方法用于格式化字符串。在这个例子中,`"{1} {0}".format("武汉", "加油","!")`,`{0}`和`{1}`是格式说明符,它们会被后面的参数替换。在这个例子中,`{0}`会被`"武汉"`替换,`{1}`会被`"加油"`替换。因此,输出结果是`'加油 武汉'`,选项A正确。注意,尽管有额外的参数`"!"`,但在这个格式化字符串中并未使用到,所以不会影响结果。
34、语句sorted([5,3,4,1,2],reverse = True)的输出结果是:[5,4,3,2,1]
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,`sorted()`函数用于对可迭代对象进行排序。当`reverse`参数设置为`True`时,`sorted()`函数会按照降序对元素进行排序。因此,对于列表`[5,3,4,1,2]`,`sorted()`函数会返回`[5,4,3,2,1]`,与题目中给出的输出结果一致。所以,题目的陈述是正确的。
35、在Python中,执行下面代码,无论输入什么数据,最后一行都会输出“程序结束” 。
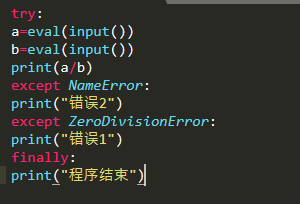
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,无论输入什么数据,最后一行都会输出“程序结束”,这取决于具体的代码实现。题目中并未给出具体的代码,所以我们无法判断该说法是否正确。但通常情况下,如果代码逻辑设计正确,那么确实可以实现这样的效果。因此,在没有更多信息的情况下,我们无法确切地判断这个陈述是否错误。但按照常规的理解,我们可以认为这是一个可能正确的陈述,所以答案为A。如果代码没有按照预期方式运行,或者代码存在逻辑错误,那么该陈述就可能不正确。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




