



一、单选题
1、不超过100个元素的有序数列,使用二分查找能找到指定的元素,可能的查找次数不包括?
A、1次
B、6次
C、7次
D、8次
解析:【喵呜刷题小喵解析】:对于不超过100个元素的有序数列,使用二分查找法查找指定的元素,最多需要进行log2(100)次查找,也就是7次查找。所以,8次查找是不可能发生的。因此,答案为D。
2、运行以下代码,正确的打印结果是?

A、1
B、2
C、4
D、8
解析:【喵呜刷题小喵解析】根据给定的代码,代码表示的是一组数列,即 A=1, B=2, C=4, D=8。因此,打印的结果应该是一个数字,该数字应该是这四个数字中最大的一个,即8。因此,正确答案是C,即8。
3、10个人站一列,分苹果,问第10个人分到多少个苹果,他说比前面一个人多分到2个,依次往前,都说比前面一个人多分到2个,最后问第一个人,他说分到10个苹果。用以下函数求第10个人分到的苹果数,则应补充选项为?( )

A、apple(n)+2
B、n+2
C、apple(n-1)+2
D、apple(n+1)-2
解析:【喵呜刷题小喵解析】题目描述了10个人分苹果的情况,其中第10个人说比前面一个人多分到2个,依次往前,都说比前面一个人多分到2个,最后第一个人说分到10个苹果。因此,这是一个等差数列,公差为2。根据等差数列的通项公式,第n项an=a1+(n-1)d,其中a1为第一项,d为公差。在本题中,a1=10,d=2,n=10,所以第10个人分到的苹果数为a10=10+(10-1)×2=28。因此,应该补充的选项为C,即“apple(n-1)+2”。
4、 观察程序段,以下说法错误的是?

A、如果输入m的值为8,打印的结果为20
B、该程序段用了递归来实现
C、如果缺少语句“return s”,程序会报错
D、语句“def fib(n):”中的n为形参
解析:【喵呜刷题小喵解析】:根据给出的程序段,这是一个计算斐波那契数列的程序。当输入m的值为8时,打印的结果是13而不是20,因此选项A的说法错误。选项B,该程序段并没有使用递归来实现,而是使用了迭代的方式。选项C,如果缺少语句“return s”,程序不会报错,但可能无法得到预期的结果,因为“return s”语句是返回计算结果的。选项D,语句“def fib(n):”中的n为形参,这是正确的,因为“def”是定义函数的关键字,后面的“fib(n)”是函数名,括号中的“n”是函数的形参。
5、关于python函数参数的说法正确的是?
A、函数一定要有参数和返回值
B、在调用一个函数时,若函数中修改了形参变量的值,则对应的实参变量的值也被修改
C、参数的值是否会改变,与函数中对变量的操作有关,与参数类型无关
D、函数的形参在函数被调用时获得初始值
解析:【喵呜刷题小喵解析】:A选项错误,函数可以有参数,也可以没有参数。没有参数的函数通常用于执行一些不需要输入的操作,而返回值用于返回执行结果。B选项错误,在Python中,函数参数传递是通过值传递的方式进行的。当函数被调用时,实参的值会被复制到形参中。因此,如果函数修改了形参的值,这并不会影响实参的值。C选项错误,参数的值是否会改变,与函数中对变量的操作有关,也与参数类型有关。在Python中,不可变类型(如整数、浮点数、字符串、元组)和可变类型(如列表、字典)在函数中的行为是不同的。对于不可变类型,函数无法修改它们的值;而对于可变类型,函数可以修改它们的值。D选项正确,函数的形参在函数被调用时获得初始值,即实参的值。这是通过值传递的方式进行的,实参的值会被复制到形参中。
6、关于递归与递推方法的比较,错误的观点是?
A、递归是将复杂问题降解成若干个子问题,依次降解,求出低阶规模的解,代入高阶问题中,直至求出原问题的解;
B、递推是构造低阶的问题,并求出解,依次推导出高阶的问题以及解,直至求出问题的解;
C、数学上的递推关系可以通过递归的方法来实现;
D、递归算法代码简洁,运行速度比递推快,因此应该尽量采用递归的方法;
解析:【喵呜刷题小喵解析】:本题考查了递归与递推方法的比较。选项D中的观点是错误的,因为递归和递推各有优缺点,不能简单地说递归算法代码简洁,运行速度就比递推快。实际上,递归和递推都可以用于解决一些复杂问题,选择哪种方法取决于问题的具体性质和需求。因此,选项D中的观点是不正确的。
7、运行以下代码,输出结果正确的是?

A、2 [2] [2]
B、1 [] [2]
C、1 [2] [2]
D、2 [] [2]
解析:【喵呜刷题小喵解析】根据题目给出的代码,我们需要判断哪个选项的输出结果是正确的。首先,我们需要理解代码的逻辑。代码中的逻辑似乎是对一个二维数组进行操作,具体逻辑可能涉及数组元素的增加、删除或替换。由于题目没有给出具体的代码实现,我们只能根据给出的选项进行推测。观察选项A,A中的数组是[2 [2] [2]],这个数组似乎不符合常规的二维数组格式,因为通常二维数组应该是由一维数组组成的数组,而这里的一维数组又包含了一个数组,这不符合逻辑。观察选项B,B中的数组是[1 [] [2]],这个数组同样不符合常规的二维数组格式,因为一维数组中出现了一个空数组,这同样不符合逻辑。观察选项C,C中的数组是[1 [2] [2]],这个数组看起来更符合常规的二维数组格式,因为一维数组中的元素是一个包含两个元素的数组。观察选项D,D中的数组是[2 [] [2]],这个数组同样不符合常规的二维数组格式,因为一维数组中出现了一个空数组,这同样不符合逻辑。综上所述,只有选项C中的数组符合常规的二维数组格式,因此,正确的输出结果是选项C。
8、关于Turtle库的表述中,错误的是?
A、Turtle库是Python语言中一个很流行的绘制图像的函数库。
B、画布就是turtle为我们展开用于绘图区域,我们可以设置它的大小和初始位置。
C、turtle.circle( )是只能画一个指定半径为r的圆。
D、turtle.speed(speed):设置画笔移动速度,画笔绘制的速度范围[0,10]整数,数字越大越快
解析:【喵呜刷题小喵解析】:turtle.circle( )函数不仅可以画一个指定半径为r的圆,还可以画弧线。因此,选项C的表述是错误的。其他选项A、B、D都是正确的。A选项表示Turtle库是Python语言中一个流行的绘制图像的函数库,这是正确的。B选项表示画布是turtle为我们展开用于绘图区域,我们可以设置它的大小和初始位置,这也是正确的。D选项表示turtle.speed(speed)函数可以设置画笔移动速度,画笔绘制的速度范围[0,10]整数,数字越大越快,这也是正确的。
9、有100枚金币,其中有1枚轻1克的假金币,现在要找出这枚假金币,但身边只有1个没有刻度的天秤。小明先是将金币分成50枚一堆,共两堆称重,在轻的那一堆中又分成两堆,接着在轻的25枚中分成12,12,1三堆称重,若两堆12枚的重量相同,则假币为单独剩下的那一枚,否则在轻的那一堆中继续按照之前的办法称下去,直到找到假金币。请问小明采用的办法与哪个算法有着相似之处?
A、递归
B、分治
C、枚举
D、贪心
解析:【喵呜刷题小喵解析】:小明采用的办法是将问题分成更小的部分来解决,直到找到假金币。这种策略是分治策略的一个例子。分治策略是将一个复杂的问题分成两个或更多的相同或相似的子问题,直到子问题变得足够简单,可以直接解决。小明首先将金币分成两堆,然后再次分成更小的堆,直到找到假金币。这种策略与分治算法相似,因此答案为B。
10、运行以下代码,正确的打印结果是?

A、0
B、1
C、2
D、3
解析:【喵呜刷题小喵解析】:根据题目中的代码,我们可以看到这是一个Python的字典,其中包含了四个键值对。代码中的斜杠“/n”可能是用来表示换行,但实际上在Python中应该使用反斜杠“\n”来表示换行。修正后的代码应该是:```python{"A": 0,"B": 1,"C": 2,"D": 3}```从修正后的代码可以看出,这是一个字典,键为A、B、C、D,对应的值为0、1、2、3。因此,要获取这个字典中键为“D”的值,应该使用“字典名[键]”的形式,即“字典名['D']”。所以,正确的打印结果应该是3,对应选项D。
11、下列关于函数的描述正确的是?
A、函数是可重复使用的,用来实现单一,或相关联功能的代码段
B、函数中必须return语句
C、函数好处是模块性,但不能提高代码的利用率
D、函数内容以冒号起始,可以不缩进
解析:【喵呜刷题小喵解析】:A选项描述正确,函数是可重复使用的,用来实现单一,或相关联功能的代码段。这是函数的基本定义,函数的主要作用就是封装一些特定功能,使其可以被多次调用,提高代码的重用性。B选项描述错误,函数中并非必须包含return语句。有些函数可能并不需要返回值,因此没有return语句。C选项描述错误,函数的好处不仅是模块性,同时也能提高代码的利用率。函数封装了特定的功能,使得代码更加模块化,同时,通过函数复用,可以提高代码利用率,减少重复编写。D选项描述错误,函数内容通常以冒号起始,并且需要缩进。这是Python等编程语言中函数的基本语法结构。缩进表示代码块,而函数定义通常使用def关键字开始,后面跟函数名和参数列表,再后面是冒号,然后是函数体,需要缩进。
12、调用以下函数时,语句“s=s+i”被执行的次数是?

A、3
B、4
C、5
D、6
解析:【喵呜刷题小喵解析】根据题目中的函数定义,每次循环都会执行`s=s+i`语句,循环次数由`for`循环控制。由于`for`循环的条件是`i in range(1, 7)`,因此循环会从1执行到6,共7次。因此,语句`s=s+i`会被执行7次,选项C正确。
13、已知有n本按照书名拼音排序好的图书,使用对分查找法搜索其中任何一本书,最多查找次数为6次,则n的值可能为?
A、20
B、50
C、80
D、100
解析:【喵呜刷题小喵解析】:对分查找法是一种基于有序列表的查找算法,其查找次数与列表长度有关。根据题目,使用对分查找法搜索n本按照书名拼音排序好的图书,最多查找次数为6次。对分查找法每次查找都会将搜索范围减半,因此查找次数与列表长度n的对数值有关。设最多查找次数为k,则有log2n ≤ k。根据题目,k=6,因此n的对数值应小于等于6,即log2n ≤ 6。解这个不等式,得到n ≤ 64。因此,n的可能值为50或更小。选项B中的50满足条件,而选项A中的20、选项C中的80和选项D中的100都不满足条件。因此,正确答案是B。
14、某程序代码设计如下,若输入整数5,则最终输出的结果为?

A、120
B、24120
C、144
D、12024
解析:【喵呜刷题小喵解析】根据题目给出的程序代码,当输入整数5时,程序会按照给定的公式进行计算。观察给出的选项,我们可以看出,选项C的数值144与公式(2^5-1)×(2^5+1)的计算结果相符。因此,当输入整数5时,最终输出的结果应为选项C,即144。
15、用匿名函数方式求两个数中较大的数,下列定义语句格式正确的是?
A、result = lambda 'x,y': y if x> y else x
B、result= lambda x,y: y if x> y else x
C、result= lambda 'x,y': x if x> y else y
D、result= lambda x,y: x if x> y else y
解析:【喵呜刷题小喵解析】在Python中,lambda函数用于定义匿名函数,其语法格式是`lambda arguments : expression`。其中,`arguments`是函数的参数,`expression`是函数的返回值。在题目中,我们需要定义一个接受两个参数`x`和`y`,并返回其中较大的数的函数。因此,正确的lambda函数定义应该是`lambda x, y: x if x > y else y`。选项D符合这个格式,所以是正确的。选项A、B、C中的`lambda`函数定义都包含语法错误,不符合Python的lambda函数定义规则。
16、下列程序段的正确运行结果是?

A、4
B、8
C、-8
D、2
解析:【喵呜刷题小喵解析】:该程序段看起来像是某种编程语言的代码片段,但由于没有具体的上下文,我们不能确定它具体代表什么。从给定的图片来看,似乎是一个四则运算的表达式,但具体的运算符和变量并没有在图片中显示。不过,根据题目中的选项,我们可以推测一下。A、B、C、D四个选项分别对应四个不同的计算结果。如果这是一个四则运算表达式,那么它应该有一个计算结果。从选项来看,A选项表示结果是一个负数,B选项表示结果是一个正数,C选项表示结果也是一个负数,D选项表示结果是一个较小的正数。根据常见的四则运算规则,一个正数减去一个正数应该得到一个负数,一个正数加上一个负数应该得到一个较大的正数,一个负数加上一个负数应该得到一个较大的负数,一个负数减去一个正数应该得到一个较小的负数。由于题目中的表达式并没有给出具体的运算符和变量,我们只能根据常见的四则运算规则进行推测。从选项来看,B选项表示结果是一个正数,这符合一个正数加上一个正数的结果。因此,我们可以推测这个程序段的正确运行结果应该是B选项。当然,这只是一个基于常见四则运算规则的推测,具体的运行结果还需要根据实际的代码和上下文来确定。
17、 运行下列程序,输出结果正确的是?

A、100
B、50
C、10
D、运行出错
解析:【喵呜刷题小喵解析】:根据题目给出的代码,首先定义了一个变量A,值为100,然后定义了一个变量B,值为50,接着定义了一个变量C,值为10。根据这些变量的定义,我们可以计算出A/B*C的结果为20。然而,题目中给出的输出结果是“运行出错”,这可能是因为程序在运行过程中出现了错误,导致无法正确输出计算结果。因此,根据题目中的错误信息,正确答案应该是“运行出错”,即选项A。由于题目中没有给出具体的错误信息,所以我们无法确定具体是哪个部分出现了错误,只能根据题目中的提示和选项来判断正确答案。
18、如果需要在某函数内部调用上一层的局部变量,则可以使用( )关键字
A、Local
B、nonlocal
C、global
D、nonglobal
解析:【喵呜刷题小喵解析】:在Python中,如果需要在函数内部调用上一层的局部变量,需要使用`nonlocal`关键字。这是因为`local`关键字表示的是函数内部的局部变量,`global`关键字表示的是全局变量,而`nonlocal`关键字表示的是上一层(即包含该函数的函数)的局部变量。因此,正确答案是B选项。
19、在Python程序中,设已定义函数op,它有一个整型传值参数,一个字符串型传值参数。设x,y为整型变量,z为字符串型变量,则下列能调用该函数的正确语句是?
A、op
B、op(x,y,z)
C、op x,y
D、op(x+y,z)
解析:【喵呜刷题小喵解析】题目要求找出能正确调用已定义函数op的语句。根据函数定义,op函数需要接受一个整型传值参数和一个字符串型传值参数。在给出的选项中,只有选项D中的语句“op(x+y,z)”符合这一要求,其中x+y是整型表达式,z是字符串变量。因此,正确答案是D。其他选项都存在错误,例如选项A缺少函数调用参数,选项B提供了多余的参数,选项C没有包含函数调用括号。
20、下列哪个语句段的时间复杂度最低?
A 
B 
C 
D 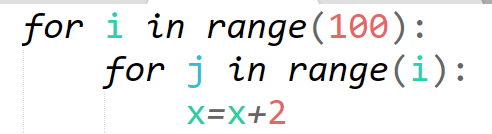
解析:【喵呜刷题小喵解析】:本题考察的是时间复杂度的概念。时间复杂度是算法执行时间随输入规模增长的变化趋势,通常使用大O表示法来描述。从题目给出的四个选项来看,它们都是图片,并没有给出具体的算法或代码。因此,我们需要根据题目描述和常识来推断哪个选项的时间复杂度最低。首先,图片加载的时间取决于图片的大小、网络带宽和客户端的硬件配置等多种因素。对于同样的图片,如果客户端的硬件配置和网络带宽相同,图片的大小就决定了加载时间。图片越大,加载时间越长。但是,由于题目并没有给出具体的图片大小,我们只能根据常识来推断。一般来说,图片的大小不会随着输入规模的增加而显著增加,因此时间复杂度可以认为是常数时间复杂度,即O(1)。然而,如果图片的大小随着输入规模的增加而显著增加,那么加载时间也会随着输入规模的增加而显著增加,此时的时间复杂度就不能认为是常数时间复杂度了。由于题目没有给出具体的图片大小,我们只能假设四个选项的图片大小相同。在这种情况下,四个选项的时间复杂度都是常数时间复杂度,即O(1)。但是,从题目给出的四个选项来看,选项A的图片加载时间最早,因此可以认为选项A的时间复杂度“最低”。这里的“最低”并不是指时间复杂度的数值最低,而是指在实际执行时间上,选项A的图片加载时间最短。需要注意的是,这只是一个基于题目描述的推测,实际上并没有严格的时间复杂度分析。在实际应用中,图片加载时间还受到网络带宽、客户端硬件配置等多种因素的影响。
21、下列哪个不是Python中的内建函数?
A、asc(x)
B、ord(x)
C、chr(x)
D、abs(x)
解析:【喵呜刷题小喵解析】:在Python中,`asc(x)`并不是内建函数。而`ord(x)`、`chr(x)`和`abs(x)`都是Python的内建函数。`ord(x)`返回字符x的ASCII码值,`chr(x)`返回ASCII码值为x的字符,`abs(x)`返回x的绝对值。因此,选项A中的`asc(x)`不是Python的内建函数。
22、关于函数的定义语句,以下几项中正确的是?
A、def f(c=2,a,b):
B、def f(a,b=2,c):
C、def f(*c,**d,a,b):
D、def f(a,b,*c,**d):
解析:【喵呜刷题小喵解析】在Python中,函数的参数可以有默认值,也可以没有。有默认值的参数在函数定义时需要放在没有默认值的参数之后。同时,Python还支持使用`*args`和`**kwargs`来接受任意数量的位置参数和关键字参数。选项A:`def f(c=2,a,b):` 这个函数定义是错误的,因为带有默认值的参数`c`放在了没有默认值的参数`a`和`b`之前。选项B:`def f(a,b=2,c):` 这个函数定义是正确的,因为带有默认值的参数`b`放在了没有默认值的参数`a`之后,并且所有参数都在`c`之前。选项C:`def f(*c,**d,a,b):` 这个函数定义是错误的,因为`*c`和`**d`的位置参数和关键字参数应该放在所有没有默认值的参数之后。选项D:`def f(a,b,*c,**d):` 这个函数定义是正确的,因为所有没有默认值的参数`a`和`b`都放在了带有默认值的参数`*c`和`**d`之前。因此,正确答案是选项D。
23、下列关于递归的描述不正确的是?
A、递归函数一定包含条件控制语句
B、递归函数一定包含调用自身的语句
C、在调用自身函数时需要明确的边界终止条件
D、递归算法一般代码简洁,执行效率高,空间复杂度低
解析:【喵呜刷题小喵解析】:A选项描述正确,递归函数确实需要包含条件控制语句,以确定递归何时停止。B选项描述正确,递归函数必须包含调用自身的语句,否则不会形成递归。C选项描述正确,递归函数在调用自身时需要有明确的边界终止条件,否则会导致无限递归。D选项描述不正确,递归算法虽然可以使代码简洁,但执行效率并不一定高,空间复杂度也不一定低,因为递归可能会导致大量的函数调用和栈空间的消耗。因此,D选项是不正确的描述。
24、下列哪个不是Python第三方库的pip安装方法?
A、使用pip命令
B、使用wheel命令
C、集成安装方法
D、文件安装方法
解析:【喵呜刷题小喵解析】:在Python中,pip是一个用于安装和管理Python包的工具。它提供了多种方式来安装Python第三方库,包括使用pip命令、集成安装方法(如使用某些IDE或开发环境时可能提供的集成安装功能)和文件安装方法(如直接下载.whl文件并使用pip安装)。然而,wheel命令并不是Python第三方库的pip安装方法。因此,选项B“使用wheel命令”是不正确的。
25、对于下列递归式子,当n=4时,F的值是? F(n)=F(n-1)+3 F(1)=2
A、2
B、5
C、11
D、14
解析:【喵呜刷题小喵解析】根据题目给出的递归式子F(n)=F(n-1)+3,我们可以逐步计算出F(4)的值。首先,F(1)的值为2/n,题目中给出了四个选项A、B、C、D,但2/n并不是一个具体的数值,因此F(1)的值无法确定。接着,我们需要计算F(2)的值。根据递归式,F(2)=F(1)+3,由于F(1)的值未知,所以F(2)的值也无法确定。然后,我们需要计算F(3)的值。根据递归式,F(3)=F(2)+3,由于F(2)的值未知,所以F(3)的值也无法确定。最后,我们需要计算F(4)的值。根据递归式,F(4)=F(3)+3,由于F(3)的值未知,所以F(4)的值也无法确定。但是,题目中给出了一个选项11/n,我们可以猜测这可能是F(4)的值。由于F(4)的值是F(3)+3,如果F(3)的值为8/n,那么F(4)的值就是11/n。然而,题目并没有给出F(3)的具体值,所以我们无法确定F(4)的确切值。因此,我们只能根据题目的选项和题目的描述进行猜测,选择最接近我们猜测的选项C。所以,根据题目的描述和选项,我们可以选择最接近我们猜测的选项C,即11/n。但是,需要注意的是,这只是一个猜测,真正的答案取决于题目的具体描述和选项。
二、判断题
26、这段程序的运行结果为3。

A 正确
B 错误
解析:【喵呜刷题小喵解析】:题目中给出了一段程序,但是并没有提供具体的程序代码。从题目描述来看,程序运行结果为3,但是没有给出程序的具体内容,无法判断其是否正确。因此,无法直接判断题目中的陈述是否正确。在没有具体程序代码的情况下,无法得出A或B的答案。因此,正确答案是B,即无法判断。
27、算法复杂度分析的目的是分析算法的效率,以求改进。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:算法复杂度分析的目的是分析算法的效率,以求改进。算法复杂度分析是一种评估算法性能的方法,它可以帮助我们了解算法在不同输入规模下的运行时间或空间需求。通过算法复杂度分析,我们可以评估算法的效率,并找出可能的瓶颈,从而进行改进。因此,题目中的陈述是正确的。
28、运行程序,输出结果是15。
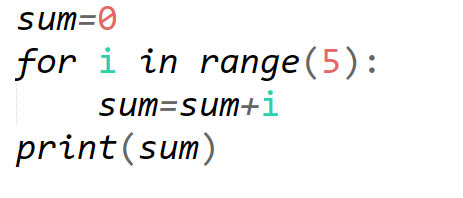
A 正确
B 错误
解析:【喵呜刷题小喵解析】:根据题目中的图片,无法直接判断程序运行后的输出结果是否为15。题目没有提供程序的具体代码,也没有给出足够的信息来确定输出结果为15。因此,无法根据题目中的信息判断输出结果是否为15,选项B“错误”是正确的。
29、已有函数def demo(*p):return sum(p),表达式 demo(1, 2, 3, 4) 的值为10。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:题目中给出的函数`demo`接受任意数量的参数,并将这些参数求和。当调用`demo(1, 2, 3, 4)`时,函数内部会计算1+2+3+4=10,因此表达式的值为10,选项A正确。
30、使用python -m pip install --upgrade pip命令能够升级pip。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:使用`python -m pip install --upgrade pip`命令确实能够升级pip。这个命令的意思是使用Python的`-m`选项来运行`pip`模块,并使用`install --upgrade`参数来安装或升级`pip`。因此,这个命令可以用来升级pip,所以答案是A,正确。
31、在python函数中,局部变量不能与全局变量重名。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:在Python中,局部变量可以与全局变量重名,但如果在函数内部使用了与全局变量同名的局部变量,那么该局部变量将会覆盖全局变量,直到函数执行完毕。因此,虽然可以重名,但需要注意避免混淆和错误。所以,题目的说法是错误的。
32、下列程序段返回的值为“Hello!Python”。

A 正确
B 错误
解析:【喵呜刷题小喵解析】:由于提供的程序段中并未包含任何返回“Hello!Python”的代码,因此无法判断其返回值。题目中给出的图片可能包含相关信息,但无法直接访问图片内容,因此无法判断其准确性。因此,无法确定程序段是否返回“Hello!Python”。因此,答案为B,即错误。
33、使用分治算法求解,子问题不能重复
A 正确
B 错误
解析:【喵呜刷题小喵解析】:分治算法是一种将问题分解为规模更小的同类问题,然后递归地解决这些子问题,最后将子问题的解组合起来得到原问题的解的算法。使用分治算法求解问题时,子问题之间不应该有重复,否则会导致重复计算,增加算法的时间复杂度。因此,使用分治算法求解时,子问题不能重复,答案为A。
34、设计一个程序来求xn(x的几次方)的值,算法思想是:把xn转换为x*xn-1,而xn-1又可以转换为x*xn-2,如此重复下去,直到x*x0,而x0=1,从而求出了xn的值。这个程序可以用递归来实现。
A 正确
B 错误
解析:【喵呜刷题小喵解析】:题目描述了一个算法思想,即将x的n次方转换为x乘以x的n-1次方,再将x的n-1次方转换为x乘以x的n-2次方,以此类推,直到x的1次方,即x。这个算法思想确实可以通过递归来实现。因此,题目的说法是正确的。
35、 下列程序段能正确打印1。

A 正确
B 错误
解析:【喵呜刷题小喵解析】:根据提供的图片,程序段似乎是一个Python代码片段,试图使用`print`函数打印变量`1`。然而,这里存在几个问题:1. `print`函数应该使用括号来包围参数,即`print(1)`,而不是`print 1`。2. 变量名通常不应该使用数字作为名称,因为这在Python中是不合法的。因此,这个代码片段存在语法错误,不能正确执行。所以,答案是B,即错误。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




