



一、单选题
1、
在程序运行过程中,CPU需要将指令从内存中取出并加以分析和执行。CPU依据( )来区分在内存中以二进制编码形式存放的指令和数据。
A、指令周期的不同阶段
B、指令和数据的寻址方式
C、指令操作码的译码结果
D、指令和数据所在的存储单元
解析:
在程序运行过程中,CPU需要从内存中取出指令并加以分析和执行。CPU依据指令周期的不同阶段来区分在内存中以二进制编码形式存放的指令和数据。取指令阶段读到的是指令,而在分析和执行指令阶段去取需要的数据。因此,正确答案是A。
2、计算机在一个指令周期的过程中,为从内存读取指令操作码,首先要将( )的内容送到地址总线上。
A、指令寄存器(IR)
B、通用寄存器(GR)
C、程序计数器(PC)
D、状态寄存器(PSW)
解析:
在计算机执行指令的过程中,程序计数器(PC)用于存储下一条要执行的指令在内存中的地址。当需要从内存读取指令操作码时,计算机首先会将PC中的内容送到地址总线上,通过地址总线寻址获取相应的指令。因此,正确答案为C。
3、
设16位浮点数,其中阶符1位、阶码值6位、数符1位、尾数8位。若阶码用移码表示,尾数用补码表示,则该浮点数所能表示的数值范围是( )。
A、-2的64 次方~(1-2的-8方)2的64次方
B、-2的63次方~(1-2的-8次方)2的63次方
C、-(1-2的-8次方)2的64次方 ~(1-2的-8次方)2的64次方
D、-(1-2的-8次方)2的63次方 ~(1-2的-8次方)2的63次方
解析:
对于此浮点数表示法,阶码(包括阶符)用移码表示,尾数(包括数符)用补码表示。根据计算机中浮点数的表示原理,阶码用于表示指数,尾数用于表示小数部分。考虑到阶码的移码表示和尾数的补码表示,我们可以计算出该浮点数所能表示的数值范围。具体计算涉及指数和尾数的最小值和最大值,以及它们所能组合成的最大和最小的浮点数。因此,正确答案应该是 B 选项:-2的63次方~(1-2的-8次方)2的63次方。
4、已知数据信息为16位,最少应附加( )位校验位,以实现海明码纠错。
A、3
B、4
C、5
D、6
解析:
海明码的构造方法是:在数据位之间插入校验位,通过扩大码距来实现检错和纠错。已知数据为16位时,根据海明码的构造原理,需要确定校验位的数量。根据公式2^K - 1≥n+k(其中n为数据位,k为校验位),代入n=16,通过计算可得至少需要5位校验位,因此答案为C。
5、将一条指令的执行过程分解为取指、分析和执行三步,按照流水方式执行,若取指时间t取指=4△t、分析时间t分析=2△t、执行时间t执行=3△t,则执行完100条指令,需要的时间为( )△t。
A、200
B、300
C、400
D、405
解析:
题目给出的执行过程是将一条指令的执行过程分解为取指、分析和执行三步,并且给出了每一步的时间。根据题意,执行完一条指令的总时间为t取指+t分析+t执行=4△t+2△t+3△t=9△t。执行完100条指令的时间为第一条指令的时间加上其余99条指令的时间。由于指令间流水方式执行,不存在时间上的叠加,所以执行完100条指令需要的时间为t总=t第一条指令+(100-1) * t执行时间中最大的时间。即t总=4△t + (100-1) * 4△t = 405△t。因此,执行完100条指令需要的时间为405△t,答案为D。
6、以下关于Cache与主存间地址映射的叙述中,正确的是( )。
A、操作系统负责管理Cache与主存之间的地址映射
B、程序员需要通过编程来处理Cache与主存之间的地址映射
C、应用软件对Cache与主存之间的地址映射进行调度
D、由硬件自动完成Cache与主存之间的地址映射
解析:
关于Cache与主存间的地址映射,确实是由硬件自动完成的。这是为了提升存储系统的访问速度,采用Cache技术时,地址映射是自动进行的,不需要操作系统、程序员或应用软件的干预。因此,正确的选项是D。
7、可用于数字签名的算法是( )。
A、RSA
B、IDEA
C、RC4
D、MD5
解析:
RSA算法是典型的非对称加密算法,主要具有数字签名和验签的功能。而IDEA和RC4都是对称加密算法,主要用于数据加密。MD5算法是消息摘要算法,用于生成消息摘要,并不适用于数字签名。因此,可用于数字签名的算法是RSA。
8、( )不是数字签名的作用。
A、接收者可验证消息来源的真实性
B、发送者无法否认发送过该消息
C、接收者无法伪造或篡改消息
D、可验证接收者合法性
解析:
数字签名的主要作用是验证消息的来源是否真实,确保消息完整性,以及防止发送者否认发送过的消息。而验证接收者的合法性不是数字签名的作用。因此,选项D是正确答案。
9、在网络设计和实施过程中要采取多种安全措施,其中( )是针对系统安全需求的措施。
A、设备防雷击
B、入侵检测
C、漏洞发现与补丁管理
D、流量控制
解析:
在网络设计和实施过程中,针对系统安全需求的措施是漏洞发现与补丁管理。设备防雷击属于物理线路安全措施,入侵检测和流量控制属于网络安全措施。因此,选项C是正确的。
10、( )的保护期限是可以延长的。
A、专利权
B、商标权
C、著作权
D、商业秘密权
解析:
商标权的保护期限是可以延长的。我国注册商标的有效期为十年,自核准注册之日起计算。注册商标有效期满,可以通过一定程序续展,延续原注册商标的有效期限,使商标注册人继续保持其注册商标的专用权。而专利权、著作权和商业秘密权的保护期限通常是固定的,不能延长。
11、甲公司软件设计师完成了一项涉及计算机程序的发明。之后,乙公司软件设计师也完成了与甲公司软件设计师相同的涉及计算机程序的发明。甲、乙公司于同一天向专利局申请发明专利。此情形下,( )是专利权申请人。
A、甲公司
B、甲、乙两公司
C、乙公司
D、由甲、乙公司协商确定的公司
解析:
根据专利法的相关规定,当两个以上的申请人分别就同样的发明创造申请专利的,专利权授给最先申请的人。如果甲、乙公司在同一天就相同的发明创造申请发明专利,应当在收到专利行政管理部门的通知后自行协商确定申请人。因此,选项D“由甲、乙公司协商确定的公司”是正确答案。
12、甲、乙两厂生产的产品类似,且产品都使用“B"商标。两厂于同一天向商标局申请商标注册,且申请注册前两厂均未使用“B"商标。此情形下,( )能核准注册
A、甲厂
B、由甲、乙厂抽签确定的厂
C、乙厂
D、甲、乙两厂
解析:
根据商标法规定,当两个或多个申请人在同一天申请商标注册且均未使用该商标时,商标局无法直接核准其中一个申请人的注册。在这种情况下,商标局会要求申请人之间进行协商,确定商标的归属。如果协商无法达成一致,商标局会采取抽签的方式决定商标的归属。因此,在此情形下,会由甲、乙厂抽签确定的厂能核准注册。
13、
在FM方式的数字音乐合成器中,改变数字载波频率可以改变乐音的( ),
A、音调
B、音色
C、音高
D、音质
解析:
在FM方式的数字音乐合成器中,改变数字载波频率可以改变乐音的音调。因此,正确答案是A。
14、在FM方式的数字音乐合成器中,,改变它的信号幅度可以改变乐音的( )。
A、音调
B、音域
C、音高
D、带宽
解析:
在FM方式的数字音乐合成器中,改变信号幅度可以改变乐音的音高。因此,正确答案是C。
15、结构化开发方法中,( )主要包含对数据结构和算法的设计。
A、体系结构设计
B、数据设计
C、接口设计
D、过程设计
解析:
在结构化开发方法中,过程设计主要包含对数据结构和算法的设计。体系结构设计主要关注系统的整体架构和模块划分,数据设计则关注数据的存储、管理和使用,接口设计则涉及到系统各部分之间的通信和交互。因此,本题答案为D。
16、在敏捷过程的开发方法中,( )使用了迭代的方法,其中,把每段时间(30天)一次的迭代称为一个“冲刺”,并按需求的优先级别来实现产品,多个自组织和自治的小组并行地递增实现产品。
A、极限编程XP
B、水晶法
C、并列争球法
D、自适应软件开发
解析:
并列争球法(Scrum)使用迭代的方法,其中把每30天一次的迭代称为一个"冲刺",并按需求的优先级别来实现产品。多个自组织和自治的小组并行地递增实现产品,并通过简短的日常情况会议进行协调。因此,根据题目描述,正确答案是C。
17、某软件项目的活动图如下图所示,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的数字表示相应活动的持续时间(天),则完成该项目的最少时间为( )天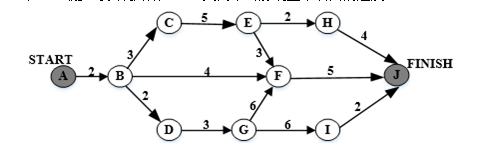
A、11
B、15
C、16
D、18
解析:
根据提供的软件项目活动图,我们需要找出项目中的关键路径,即完成所有活动所需的最长路径。关键路径上的任何延迟都会导致整个项目的延迟。
从图中可以看出,项目的主要里程碑和活动包括:
- A到B(持续3天)
- B到C(持续4天)
- C到E(持续2天,依赖C完成)
- E到F(持续3天)
- F到J(持续最后一天)
关键路径为ABCEF,总时间为:3(A到B)+ 4(B到C)+ 2(C到E)+ 3(E到F)= 12天。但是这里还有一条从B直接到J的路径,它可以在关键路径的某个环节并行进行以节省时间。具体的并行点是E到F的期间,可以插入一个并行活动从B直接到J,持续时间为最后一天。因此,总时间可以减少最后一天的活动时间,变为最短完成时间:总时间减去最后一天的活动持续时间即为完成项目的最少时间,即18 - 1 = 17天。但因为选项中没有给出具体活动可能存在的并行性所带来的影响,因此以最直观的关键路径计算为准。所以完成该项目的最少时间为D选项的18天。
18、某软件项目的活动图如下图所示,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的数字表示相应活动的持续时间(天),活动BC和BF最多可以晚开始( )天而不会影响整个项目的进度。
A、0和7
B、0和11
C、2和7
D、2和11
解析:
根据题目给出的软件项目活动图,我们可以通过分析最短工期路径来确定活动BC和BF最多可以晚开始的天数。
最短工期路径是ABCEFJ或ABDGFJ,时间是18天。在这条路径上,活动BC是最关键的,因为它在最短路径上,所以BC活动不能有任何延误,即BC活动最晚开始时间为0天。
对于活动BF,我们可以分析它的后续活动FJ,FJ活动在路径上的持续时间是固定的,无法减少。但是BF活动的持续时间不影响FJ活动的开始时间,因此我们可以调整BF活动的持续时间以腾出时间缓冲。根据活动持续时间计算,BF活动可以晚开始的时间为总持续时间减去其后续活动的持续时间,即总持续时间减去FJ活动的持续时间(假设为总天数减去FJ活动的天数),从而不影响整个项目的进度。根据题目给出的信息,BF活动可以晚开始的时间为总天数减去FJ活动的天数减去BF活动到FJ活动的间隔时间(假设为固定的时间间隔),也就是7天。因此,活动BC和BF最多可以晚开始的天数是0天和7天。
19、成本估算时,( )方法以规模作为成本的主要因素,考虑多个成本驱动因子。该方法包括三个阶段性模型,即应用组装模型、早期设计阶段模型和体系结构阶段模型。
A、专家估算
B、Wolverton
C、COCOMO
D、COCOMO Ⅱ
解析:
根据题目描述,该成本估算方法包括三个阶段性模型,即应用组装模型、早期设计阶段模型和体系结构阶段模型。这是COCOMOⅡ方法的特征。因此,正确答案是D,即COCOMOⅡ。
20、逻辑表达式求值时常采用短路计算方式。“&&"、“||”、“!”分别表示逻辑与、或、非运算,“&&”、“||”为左结合,“!”为右结合,优先级从高到低为 “!”、“&&”、“||”。对逻辑表达式“x&&(y || !z)”进行短路计算方式求值时,( )。
A、x为真,则整个表达式的值即为真,不需要计算y和z的值
B、x为假,则整个表达式的值即为假,不需要计算y和z的值
C、x为真,再根据z的值决定是否需要计算y的值
D、x为假,再根据y的值决定是否需要计算z的值
解析:
根据逻辑表达式的短路计算方式,"x && (y || !z)“中,如果x为假,则整个表达式的值即为假,不需要进一步计算y和z的值。这是因为逻辑与运算”&&"具有左结合性,并且一旦确定整个表达式的值为假,就没有必要继续计算后续的部分。因此,选项B正确。
21、常用的函数参数传递方式有传值与传引用两种。( )。
A、在传值方式下,形参与实参之间互相传值
B、在传值方式下,实参不能是变量
C、在传引用方式下,修改形参实质上改变了实参的值。
D、在传引用方式下,实参可以是任意的变量和表达式。
解析:
传值调用中,形参与实参之间是相互独立的,形参的修改不会影响实参的值。而在传引用方式下,形参和实参共享同一个内存地址,因此修改形参的值会直接影响实参的值。所以选项C描述正确。选项A描述不准确,因为在传值方式下,形参与实参之间没有直接的相互影响。选项B描述错误,因为在传值方式下,实参可以是变量。选项D描述不全面,因为在传引用方式下,实参必须是变量,但不能是任意表达式。
22、二维数组a[1..N,1..N]可以按行存储或按列存储。对于数组元素a[i,j](1<=i,j<=N),当( )时,在按行和按列两种存储方式下,其偏移量相同。
A、i≠j
B、i=j
C、i>j
D、i<j
解析:
对于二维数组a[1..N,1..N],无论是按行存储还是按列存储,对于数组元素a[i,j],当i=j时,该元素在数组中的位置(即偏移量)都是一样的。这是因为无论是按行还是按列存储,当i=j时,元素都位于数组的交叉对角线上。因此,在两种存储方式下,其偏移量相同。所以选项B正确。
23、实时操作系统主要用于有实时要求的过程控制等领域。实时系统对于来自外部的事件必须在( )。
A、一个时间片内进行处理
B、一个周转时间内进行处理
C、一个机器周期内进行处理
D、被控对象规定的时间内做出及时响应并对其进行处理
解析:
实时操作系统主要用于有实时要求的过程控制等领域,对于来自外部的事件,实时系统必须在被控对象规定的时间内做出及时响应并对其进行处理。实时操作系统(Real Time Operating System,RTOS)的特点是能及时响应外部事件的请求,并在规定的时间内完成对该事件的处理,同时控制所有实时任务协调一致地运行。因此,正确答案是D。
24、假设某计算机系统中只有一个CPU、一台输入设备和一台输出设备,若系统中有四个作业T1、T2、T3和T4,系统采用优先级调度,且T1的优先级>T2的优先级>T3的优先级>T4的优先级。每个作业Ti具有三个程序段:输入Ii、计算Ci和输出Pi(i=1,2,3,4),其执行顺序为Ii→Ci→Pi。这四个作业各程序段并发执行的前驱图如下所示。图中①、②分别为( )
A、l2、P2
B、l2、C2
C、C1、P2
D、C1、P3
解析:
根据题目描述,每个作业Ti的执行顺序为输入I~i~、计算C~i~和输出P~i~~。由于系统中只有一个CPU,因此计算阶段C~i~必须等待输入阶段I~i~完成后才能开始执行。同样,输出阶段P~i~~必须等待计算阶段C~i~完成后才能开始执行。根据作业的优先级顺序T1>T2>T3>T4,优先级高的作业会优先执行。因此,在作业T1的输入阶段完成后,CPU会开始执行其计算阶段C1,接着执行作业T2的输入阶段I2。由于题目中给出的前驱图中有两个空位①和②,结合上述分析,可以推断出①表示的是计算阶段C1,而②表示的是输出阶段P2。因此,正确答案为C,即①为C1,②为P2。
25、假设某计算机系统中只有一个CPU、一台输入设备和一台输出设备,若系统中有四个作业T1、T2、T3和T4,系统采用优先级调度,且T1的优先级>T2的优先级>T3的优先级>T4的优先级。每个作业Ti具有三个程序段:输入Ii、计算Ci和输出Pi(i=1,2,3,4),其执行顺序为Ii→Ci→Pi。这四个作业各程序段并发执行的前驱图如下所示。图中③、④、⑤分别为( )。
A、C2、C4、P4
B、 l2、l3、C4
C、I3、P3、P4
D、 l3、C4、P4
解析:
根据题目描述,系统中的作业T1、T2、T3和T4各有三个程序段:输入、计算和输出。由于只有一个CPU,这些程序段需要按照优先级顺序并发执行。题目中给出了优先级顺序为T1 > T2 > T3 > T4。结合题目中的前驱图,我们可以推断出执行的顺序。根据图中的节点,我们可以确定①和②分别表示C1和P3的执行。对于③、④、⑤的位置,由于它们是后续的执行节点,且根据优先级顺序,我们可以确定它们分别表示I3、C4和P4的执行。因此,正确答案为D:I3、C4、P4。
26、
假设段页式存储管理系统中的地址结构如下图所示,则系统( )。
A、最多可有256个段,每个段的大小均为2048个页,页的大小为8K
B、最多可有256个段,每个段最大允许有2048个页,页的大小为8K
C、最多可有512个段,每个段的大小均为1024个页,页的大小为4K
D、最多可有512个段,每个段最大允许有1024个页,页的大小为4K
解析:
根据题目中的地址结构图,可以得知段页式存储管理系统中的地址由段号、页号和页内地址三部分组成。其中,段号占8位,页号占11位,页内地址占13位。
根据这些信息,我们可以计算出每个段的页数和页的大小。由于页号占11位,所以最大可以有2^11=2048个页。而页内地址占13位,决定了页内地址的最大空间,即页的大小。常见的页大小有4K、8K等,但题目中并未明确给出页的大小。
因此,根据题目给出的选项,最多可有256个段(由段号占8位决定),每个段最大允许有2048个页(由页号占11位决定),但页的具体大小并未在题目中明确给出。所以,选项B是正确的。
27、假设系统中有n个进程共享3台扫描仪,并采用PV操作实现进程同步与互斥。若系统信号量S的当前值为-1,进程P1、P2又分别执行了1次P(S)操作,那么信号量S的值应为( )。
A、3
B、-3
C、1
D、-1
解析:
本题考查的是操作系统PV操作方面的知识。PV操作是进程同步与互斥的一种实现方式,其中P操作用于获取资源,V操作用于释放资源。系统中有n个进程共享3台扫描仪,信号量S的初值应为3,表示有3个扫描仪可供进程使用。当系统信号量S的当前值为-1时,表示已经有一个进程获取了扫描仪并正在进行使用。当P1和P2进程分别执行P(S)操作时,它们都会尝试获取扫描仪资源。由于只有一个进程可以获得资源,另外两个进程会等待,因此信号量S的值会递减。因此,当P1进程执行P(S)操作时,信号量S的值变为-2;当P2进程执行P(S)操作时,信号量S的值变为-3。所以,信号量S的值应为-3,选项B正确。
28、
某字长为32位的计算机的文件管理系统采用位示图(bitmap)记录磁盘的使用情况。若磁盘的容量为300GB,物理块的大小为1MB,那么位示图的大小为( )个字。
A、1200
B、3200
C、6400
D、9600
解析:
根据题目描述,我们需要先计算磁盘的容量转换为MB,即300GB等于多少MB。根据换算规则,1GB等于1024MB,所以300GB等于300乘以1024MB。
接下来,我们需要计算需要多少物理块来记录磁盘的使用情况。每个物理块的大小为1MB,所以需要的物理块数量就是磁盘容量(MB)除以物理块大小(MB)。
然后,我们需要考虑位示图的大小。每个字可以标记32个物理块的使用情况。因此,位示图的大小(以字为单位)等于需要的物理块数量除以每字可标记的物理块数量。计算结果是9600个字。
所以,正确答案是D。
29、某开发小组欲为一公司开发一个产品控制软件,监控产品的生产和销售过程,从购买各种材料开始,到产品的加工和销售进行全程跟踪。购买材料的流程、产品的加工过程以及销售过程可能会发生变化。该软件的开发最不适宜采用( )模型
A、瀑布
B、原型
C、增量
D、喷泉
解析:
对于需要监控产品的生产和销售过程,且这些流程可能会变化的软件项目,其需求往往难以在前期完全确定。瀑布模型是一种传统的软件开发过程模型,它强调早期的需求定义和规格制定,然后依次进行设计和编码等工作。由于这种模型侧重于早期需求的明确和固定,对于需求可能会变化的软件项目,瀑布模型可能不太适应。因此,该软件的开发最不适宜采用瀑布模型。
30、某开发小组欲为一公司开发一个产品控制软件,监控产品的生产和销售过程,从购买各种材料开始,到产品的加工和销售进行全程跟踪。购买材料的流程、产品的加工过程以及销售过程可能会发生变化。该软件的开发最不适宜采用一种模型,主要是因为这种模型( )。
A、不能解决风险
B、不能快速提交软件
C、难以适应变化的需求
D、不能理解用户的需求
解析:
根据题目描述,开发小组需要开发一个产品控制软件,监控产品的生产和销售过程,并且这些流程可能会发生变化。在这种情况下,瀑布模型最不适宜采用,主要是因为瀑布模型是一种线性顺序开发模型,强调在前期确定所有需求和设计,然后按照阶段进行开发。然而,当购买材料的流程、产品的加工过程以及销售过程可能会发生变化时,瀑布模型难以适应这些变化的需求。因此,选项C“难以适应变化的需求”是正确答案。
31、( )不属于软件质量特性中的可移植性。
A、适应性
B、易安装性
C、易替换性
D、易理解性
解析:
可移植性主要包括适应性、易安装性、共存性和易替换性四个特性,而易理解性并不属于可移植性的范畴。因此,选项D不属于软件质量特性中的可移植性。
32、对下图所示流程图采用白盒测试方法进行测试,若要满足路径覆盖,则至少需要( )个测试用例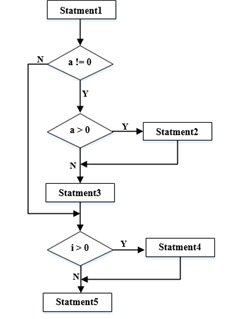
A、3
B、4
C、6
D、8
解析:
对于流程图的白盒测试,路径覆盖意味着需要确保程序中的每条路径至少被执行一次。根据提供的流程图,我们可以数出有6条不同的路径:1-2-3-4-5-6-7-8,1-2-3-4-5-6-8,1-2-3-5-6-7-8,1-2-3-5-6-8,1-2-6-7-8和1-2-6-8。因此,为了满足路径覆盖,至少需要6个测试用例。所以答案是C。
33、
对下图所示流程图采用McCabe度量法计算该程序的环路复杂性为( )。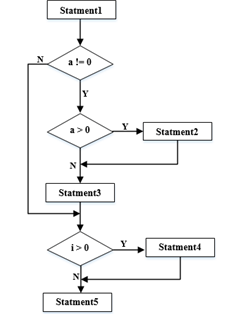
A、1
B、2
C、3
D、4
解析:
:根据McCabe度量法,环形复杂度V(G)的计算公式为V(G)=E-N+2,其中E是流图中边的条数,N是结点数。根据题目中的流程图,边的条数E为10,结点数N为8,代入公式计算得V(G)=10-8+2=4。因此,该程序的环路复杂性为4,答案为D。
34、计算机系统的( )可以用MTBF/(1+MTBF)来度量,其中MTBF为平均失效间隔时间。
A、可靠性
B、可用性
C、可维护性
D、健壮性
解析:
根据题目描述,MTBF为平均失效间隔时间,而计算机系统的可用性通常使用MTBF与MTTR的比值来度量,其中MTTR为平均修复时间。因此,题目中的表达式MTBF/(1+MTBF)可以用来度量计算机系统的可用性。所以正确答案为B。
35、以下关于软件测试的叙述中,不正确的是( )。
A、在设计测试用例时应考虑输入数据和预期输出结果
B、软件测试的目的是证明软件的正确性
C、在设计测试用例时,应该包括合理的输入条件
D、在设计测试用例时,应该包括不合理的输入条件
解析:
软件测试的目的是为了发现软件中的错误、缺陷和不足,而不是证明软件的正确性。因此,选项B是不正确的叙述。设计测试用例时应该考虑输入数据和预期输出结果,包括合理的输入条件以及不合理的输入条件,以便全面测试软件的性能和功能。因此,选项A、C和D都是正确的。
36、
某模块中有两个处理A和B,分别对数据结构X写数据和读数据,则该模块的内聚类型为( )内聚。
A、逻辑
B、过程
C、通信
D、内容
解析:
根据题目描述,模块中的处理A和B分别负责数据结构X的写数据和读数据,这表明这两个处理之间存在通信关系,即处理A将数据处理后传递给处理B进行进一步的操作。因此,该模块的内聚类型为通信内聚。
37、
在面向对象方法中,不同对象收到同一消息可以产生完全不同的结果,这一现象称为( )。在使用时,用户可以发送一个通用的消息,而实现的细节则由接收对象自行决定。
A、接口
B、继承
C、覆盖
D、多态
解析:
在面向对象方法中,不同对象收到同一消息可以产生完全不同的结果,这一现象称为多态。多态允许用户发送一个通用的消息,而实现的细节则由接收对象自行决定。因此,选项D是正确的。
38、
在面向对象方法中,支持多态的是( )。
A、静态分配
B、动态分配
C、静态类型
D、动态绑定
解析:
在面向对象方法中,多态是通过动态绑定来实现的。动态绑定是指在运行时确定对象所调用的方法,从而实现不同对象调用相同方法时表现出不同的行为。因此,选项D“动态绑定”是支持多态的。而选项A静态分配、选项B动态分配、选项C静态类型虽然都是面向对象编程中的概念,但它们并不直接支持多态。
39、面向对象分析的目的是为了获得对应用问题的理解,其主要活动不包括( )。
A、认定并组织对象
B、描述对象间的相互作用
C、面向对象程序设计
D、确定基于对象的操作
解析:
面向对象分析的目的是为了获得对应用问题的理解,其主要活动包括认定并组织对象、描述对象间的相互作用以及确定基于对象的操作。因此,选项A、B和D都是面向对象分析的主要活动。而选项C,面向对象程序设计,并不是面向对象分析的主要活动,而是面向对象设计或实现的部分内容。
40、如下所示的UML状态图中,( )时,不一定会离开状态B

A、状态B中的两个结束状态均达到
B、在当前状态为B2时,事件e2发生
C、事件e2发生
D、事件e1发生
解析:
根据UML状态图,状态B包含多个子状态,如B1、B2等。只有在状态B2下发生事件e2时,才会离开状态B。因此,如果事件e2发生在状态B的其他子状态下,或者事件e1发生,都不会导致离开状态B。所以选项C是正确的。
41、
以下关于UML状态图中转换(transition)的叙述中,不正确的是( )。
A、活动可以在转换时执行也可以在状态内执行
B、监护条件只有在相应的事件发生时才进行检查
C、一个转换可以有事件触发器、监护条件和一个状态
D、事件触发转换
解析:
关于UML状态图中的转换,选项C描述不正确。一个转换通常包括事件触发器、监护条件(可选)和一个或多个目标状态,但不能包括一个状态。状态是转换存在的环境,转换是状态之间的迁移路径。其他选项描述是正确的,活动可以在转换时执行也可以在状态内执行,监护条件确实是在相应的事件发生时进行检查,事件触发转换。因此,不正确的叙述是C。
42、
下图①②③④所示是UML( )。现有场景:一名医生(Doctor)可以治疗多位病人(Patient),一位病人可以由多名医生治疗,一名医生可能多次治疗同一位病人。要记录哪名医生治疗哪位病人时,需要存储治疗(Treatment)的日期和时间。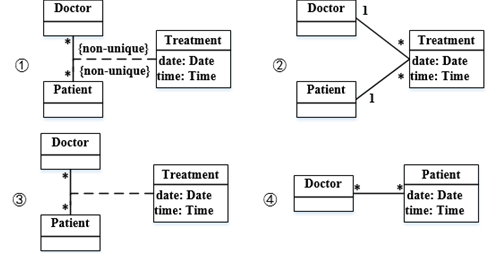
A、用例图
B、对象图
C、类图
D、协作图
解析:
题目描述了一个医生(Doctor)与病人(Patient)之间的关系,以及治疗(Treatment)的日期和时间需要被记录。在UML中,类图用于描述系统中的类和它们之间的关系。根据题目描述,医生与病人之间是多对多的关系,且需要记录治疗的信息,这可以通过类图来清晰地表示类和关系,并定义属性如治疗的日期和时间。因此,最符合题意的答案是C,即类图。
43、现有场景:一名医生(Doctor)可以治疗多位病人(Patient),一位病人可以由多名医生治疗,一名医生可能多次治疗同一位病人。要记录哪名医生治疗哪位病人时,需要存储治疗(Treatment)的日期和时间。以下①②③④图中( )。是描述此场景的模型。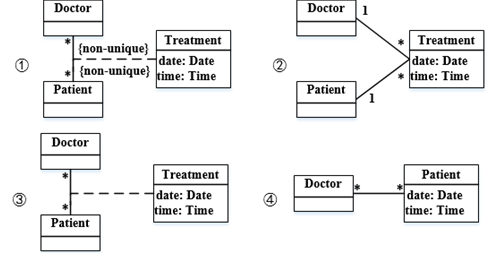
A、①
B、②
C、③
D、④
解析:
根据题目描述,一名医生可以治疗多位病人,一位病人也可以由多名医生治疗,同时需要记录治疗的日期和时间。这表示医生和病人之间是多对多的关系,同时需要记录治疗的时间。在提供的图中,①图能够体现医生和病人的多对多关系,并且可以治疗时间作为一个属性进行记录,符合题目的描述。因此,正确答案是A。
44、( )模式定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换,使得算法可以独立于使用它们的客户而变化
A、命令(Command)
B、责任链(Chain of Responsibility)
C、观察者(Observer)
D、策略(Strategy)
解析:
策略模式定义了一系列的算法,并将这些算法封装起来,使得它们可以相互替换,从而使得算法可以独立于使用它们的客户而变化。根据题目描述,策略模式符合题目的要求,所以答案为D。
45、
某模式定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换,使得算法可以独立于使用它们的客户而变化。以下( )情况适合选用该模式。
①一个客户需要使用一组相关对象
②一个对象的改变需要改变其它对象
③需要使用一个算法的不同变体
④许多相关的类仅仅是行为有异
A、①②
B、②③
C、③④
D、①④
解析:
策略模式主要用于处理需要使用一组算法中的某一个的情况,或者算法在未来可能会有其他实现的情况。对于题目中的描述,需要使用一个算法的不同变体以及许多相关的类仅仅是行为有异,符合策略模式的应用场景。因此,选项C是正确答案。
46、( )模式将一个复杂对象的构建与其表示分离,使得同样的构建过程可以创 建不同的表示。
A、生成器(Builder)
B、工厂方法(Factory Method)
C、原型(Prototype)
D、单例( Singleton)
解析:
生成器模式将一个复杂对象的构建与它的表示分离,通过生成器对象来构建复杂对象的不同表示形式。因此,题目的描述与生成器模式相符,故选A。
47、
某模式将一个复杂对象的构建与其表示分离,使得同样的构建过程可以创建不同的表示。以下( )情况适合选用该模式。
①抽象复杂对象的构建步骤
②基于构建过程的具体实现构建复杂对象的不同表示
③一个类仅有一个实例
④一个类的实例只能有几个不同状态组合中的一种
A、①②
B、②③
C、③④
D、①④
解析:
根据题目描述,该模式将一个复杂对象的构建与其表示分离,使得同样的构建过程可以创建不同的表示。这意味着该模式适用于以下两种情况:①抽象复杂对象的构建步骤,这样可以使构建过程独立于具体表示,更加灵活;②基于构建过程的具体实现构建复杂对象的不同表示。因此,选项A(①②)是正确的选择。选项B(②③)不正确,因为题目中的模式并不涉及一个类仅有一个实例或一个类的实例只能有几种不同状态组合中的一种。选项C(③④)和D(①④)也不完全正确,因为它们没有涵盖该模式适用的所有情况。
48、
由字符a、b构成的字符串中,若每个a后至少跟一个b,则该字符串集合可用正规式表示为( )。
A、(b|ab)*
B、(ab*)*
C、(a*b*)*
D、(a|b)*
解析:
由字符a、b构成的字符串中,若每个a后至少跟一个b,意味着字符串中不可能有单独的a出现,而必须有至少一个b跟随其后。因此,我们可以使用正规式来描述这种字符串集合。观察给出的选项:
A选项:(b|ab)* 表示的是字符串由b开始或者ab开始,然后可以有多个这样的组合。这符合题目要求,因为每个a后面都至少跟着一个b。
B选项:(ab*)* 表示的是字符串由ab开始,后面跟随多个任意数量的b。这并不完全符合题目的要求,因为允许连续出现多个a没有b跟随的情况。
C选项:(a*b*)* 表示的是任何数量的a和任何数量的b的组合,没有明确限制每个a后面必须有至少一个b。
D选项:(a|b)* 表示的是字符串可以由a或b开始,然后可以有多个这样的字符。这不符合题目要求,因为它允许单独的a出现。
综上所述,只有A选项符合题目描述的正规式表示方法。
49、乔姆斯基(Chomsky)将文法分为4种类型,程序设计语言的大多数语法现象可用其中的( )描述。
A、上下文有关文法
B、上下文无关文法
C、正规文法
D、短语结构文法
解析:
乔姆斯基将文法分为四种类型,其中上下文无关文法在程序设计语言中应用广泛。程序设计语言的大多数语法现象可以用上下文无关文法来描述。因此,答案为B。
50、
运行下面的C程序代码段,会出现( )错误。
int k=0;
for(;k<100;);
{k++;}
A、变量未定义
B、静态语义
C、语法
D、动态语义
解析:
题目中的C程序代码段包含一个for循环,该循环的条件是k<100,但由于循环体为空(只有一个分号;),因此会无限循环下去,即产生死循环。这种情况属于动态语义错误,因为程序在运行时会出现问题。因此,选项D“动态语义”是正确的答案。
51、在数据库系统中,一般由DBA使用DBMS提供的授权功能为不同用户授权,其主要目的是为了保证数据库的( )。
A、正确性
B、安全性
C、一致性
D、完整性
解析:
在数据库系统中,DBA(数据库管理员)使用DBMS(数据库管理系统)提供的授权功能为不同用户授权,其主要目的是为了保证数据库的安全性。通过控制用户对数据库的访问权限,可以防止未经授权的用户访问数据,从而保护数据不被非法获取或篡改。因此,正确答案是B,即为了保证数据库的安全性。
52、给定关系模式R(U, F),其中:U为关系模式R中的属性集,F是U上的一组函数依赖。假设U={A1,A2,A3,A4},F={A1→A2,A1A2→A3,A1→A4,A2→A4},那么关系R的主键应为( )
A、A1
B、A1A2
C、A1A3
D、A1A2A3
解析:
在给定的关系模式R(U,F)中,属性集U为{A1,A2,A3,A4},函数依赖集F为{A1→A2,A1A2→A3,A1→A4,A2→A4}。根据函数依赖的性质,我们可以分析出以下结论:首先,由A1→A2和A1→A4可知,属性A1决定了属性A2和A4的值,这说明属性A1是关键属性。其次,由A1A2→A3可知,属性组合A1和A2共同决定了属性A3的值。然而,单独的属性A2并不能决定其他属性的值,因此属性组合并不能作为主键。根据以上分析,我们可以确定关系R的主键应为单独的属性A1。因此,正确答案为A。
53、
给定关系模式R(U, F),其中:U为关系模式R中的属性集,F是U上的一组函数依赖。假设U={A1,A2,A3,A4},F={A1→A2,A1A2→A3,A1→A4,A2→A4},函数依赖集F中的( )是冗余的。
A、A1→A2
B、A1A2→A3
C、A1→A4
D、A2→A4
解析:
根据题目给定的函数依赖集F,包括A1→A2,A1A2→A3,A1→A4和A2→A4。根据函数依赖的传递性,如果X→Y和Y→Z,则可以推出X→Z。在此题中,由A1→A2和A2→A4,可以推导出A1→A4。因此,函数依赖集F中的A1→A4是冗余的。
54、给定关系R(A , B , C ,D)和关系S(A ,C ,E ,F),对其进行自然连接运算 后的属性列为( )个
后的属性列为( )个
A、4
B、5
C、6
D、8
解析:
对关系R和关系S进行自然连接时,它们之间的公共字段为A和C。连接后,对于每个公共字段,只会保留一个字段名。因此,连接后的属性列包括R中的B和D,以及S中的E和F。这样,总共有6个属性列。所以,经过自然连接运算后的属性列为6个,答案为C。
55、
给定关系R(A , B , C ,D)和关系S(A ,C ,E ,F),与σR.B>S.E(R ⋈ S)等价的关系代数表达式为( )。
A、σ2>7(R x S)
B、π1,2,3,4,7,8(σ1=5^2>7^3=6(R×S))
C、σ2>'7'(R×S)
D、π1,2,3,4,7,8(σ1=5^2>’7’^3=6(R×S))
解析:
给定关系R(A,B,C,D)和关系S(A,C,E,F),与σR.B>S.E(R ⋈ S)等价的关系代数表达式为对R和S进行自然连接(Natural Join)操作后,再进行选择操作(Selection),选择条件为R中的B大于S中的E。自然连接操作保留相同的属性列,然后对结果进行投影选择特定的列。因此,选项B π1,2,3,4,7,8(σ1=5^2>7^3=6(R×S))是正确的表达式。
56、下列查询B=“大数据”且F=“开发平台”,结果集属性列为A、B、C、F的关系代数表达式中,查询效率最高的是( )
A、π1,2,3,8 (σ2='大数据' ^ 1=5 ^ 3=6 ^ 8='开发平台'(R×S))
B、π1,2,3,8 (σ1=5 ^ 3=6 ^ 8='开发平台'(σ2='大数据'(R)×S))
C、π1,2,3,8(σ2='大数据' ^ 1=5 ^ 3=6(R×σ4='开发平台'(S))
D、π1,2,3,8(σ1=5 ^ 3=6(σ2='大数据'(R)×σ4='开发平台'(S)))
解析:
此题考察的是关系代数表达式的查询效率。关系代数是一种用于表达数据库查询的语言。在这个问题中,我们需要比较不同查询路径的效率。
首先,我们需要理解题目中的关系代数表达式:
- A选项:首先对R和S进行笛卡尔积运算,然后再进行筛选操作,这种方式的计算量较大。
- B选项:首先对R进行筛选,然后与S进行笛卡尔积运算,计算量有所减少,但仍然较大。
- C选项:首先对S进行筛选,然后与R进行笛卡尔积运算,这种方式与B选项类似,计算量也较大。
- D选项:分别对R和S进行筛选,然后再进行笛卡尔积运算,这种方式能够最大程度地减少计算量,提高查询效率。
假设R有100条数据,其中B是大数据的有50条;S有100条数据,其中F是开发平台的有50条。根据这个假设,我们可以计算出各个选项的计算量:
- A选项的计算量大约是100 * 100 = 10000条新数据。
- B和C选项的计算量大约是 100 + 50 * 100 = 5100条新数据。
- D选项的计算量大约是 100 + 50 * 50 + 100 = 2700条新数据。
因此,D选项的计算量最小,查询效率最高。所以答案是D。
57、
拓扑序列是有向无环图中所有顶点的一个线性序列,若有向图中存在弧<v,w>或存在从顶点v到w的路径,则在该有向图的任一拓扑序列中,v一定在w之前。下面有向图的拓扑序列是( )。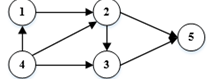
A、41235
B、43125
C、42135
D、41325
解析:
根据拓扑序列的定义,在有向无环图中,如果存在从顶点v到w的路径,则v一定在w之前。对于给定的有向图,首先确定没有前驱结点的结点,作为拓扑序列的第一个元素。然后依次确定剩余结点的前驱结点已访问完毕的结点,逐步构建拓扑序列。
根据图示的有向图,可以确定4号结点没有前驱结点,因此拓扑序列的首位是4。接下来,访问1号结点,因为存在从4到1的路径。然后访问2号结点,因为1号结点的访问已经完成。最后,可以访问3号或5号结点,因为它们没有指向其他未访问的结点。因此,拓扑序列为41235或41253。题目中给出的选项中,只有A选项符合其中一种可能的拓扑序列。所以答案是A。
58、设有一个包含n个元素的有序线性表。在等概率情况下删除其中的一个元素,若采用顺序存储结构,则平均需要移动( )个元素
A、1
B、(n-1)/2
C、logn
D、n
解析:
设有一个包含n个元素的有序线性表,在等概率情况下删除其中的一个元素,若采用顺序存储结构,需要考虑删除元素的位置对需要移动的元素个数的影响。
最好情况是删除最后一个元素,此时不用移动任何元素,直接删除。最差的情况是删除第一个元素,此时需要移动n-1个元素。因为在等概率情况下,每个元素被删除的概率是相同的,所以平均状态下需要移动的元素个数是(n-1)/2。因此,正确答案是B选项。
59、设有一个包含n个元素的有序线性表。在等概率情况下删除其中的一个元素,若采用单链表存储,则平均需要移动( )个元素。
A、 0
B、1
C、(n-1)/2
D、n/2
解析:
对于单链表存储的有序线性表,删除一个元素时,只需要调整被删除元素的前驱节点的指针,使其指向被删除元素的下一个元素,而不需要实际移动元素。因此,无论删除哪个元素,平均需要移动的元素数量都是0。
60、
具有3个节点的二叉树有( )种形态。
A、2
B、3
C、5
D、7
解析:
对于具有三个节点的二叉树,我们可以按照以下方式进行分析:
首先,第一个节点为根节点,这是必然的。然后,剩下的两个节点可以分布在根节点的左右两侧。这两个节点可以形成以下形态:左、右、或左右都有(即一个左子节点和一个右子节点)。这样,我们可以得出具有三个节点的二叉树有五种不同的形态。因此,答案为C。
61、
以下关于二叉排序树(或二叉查找树、二叉搜索树)的叙述中,正确的是( ) 。
A、对二叉排序树进行先序、中序和后序遍历,都得到结点关键字的有序序列
B、含有n个结点的二叉排序树高度为⌊log2n⌋+1
C、从根到任意一个叶子结点的路径上,结点的关键字呈现有序排列的特点
D、从左到右排列同层次的结点,其关键字呈现有序排列的特点
解析:
对于二叉排序树(二叉查找树、二叉搜索树):
A选项:对于先序、中序和后序遍历,确实可以得到结点关键字的有序序列,但这并不是二叉排序树的特性,而是任何二叉树(无论是否排序)进行遍历操作的一般结果。所以A选项描述不准确。
B选项:含有n个结点的二叉排序树的高度并不固定为⌊log2n⌋+1。高度取决于树的构造方式,最坏情况下可能接近n(不平衡树),而最好情况下接近log2n(平衡树)。因此B选项错误。
C选项:从根到任意一个叶子结点的路径上,结点的关键字确实呈现有序排列的特点。这是二叉排序树的一个基本特性,即左子结点的值小于根节点的值,右子结点的值大于根节点的值。所以C选项描述准确,但题目要求选择正确的叙述,而C选项并不是题目中的正确答案。
D选项:在同一层级的从左到右排列的结点中,其关键字是呈现有序排列的特点的。这也是二叉排序树的一个基本特性。所以D选项是正确的描述。
62、下表为某文件中字符的出现频率,采用霍夫曼编码对下列字符编码,则字符序列“bee”的编码为( );
A、10111011101
B、10111001100
C、001100100
D、110011011
解析:
根据霍夫曼编码的原理,字符序列"bee"的编码应该是每个字符霍夫曼编码的串联。根据给定的字符频率表,字符b的霍夫曼编码为101,字符e的霍夫曼编码为1011和1101。因此,"bee"的编码为b的编码+e的编码+e的编码,即101(b)+ 101(e)+ 110(第二个e),结果为1011101(总编码)。因此,"bee"的霍夫曼编码为选项A,即编码为“1011101”。
63、下表为某文件中字符的出现频率,采用霍夫曼编码对下列字符编码,编码“110001001101”的对应的字符序列为( )。
A、bad
B、bee
C、face
D、bace
解析:
根据给定的霍夫曼编码表,“1100"对应字符"f”,“0"对应字符"a”,“100"对应字符"c”,“1101"对应字符"e”。因此,编码"110001001101"对应的字符序列为face。所以正确答案是C。
64、
两个矩阵Am*n和Bn*p相乘,用基本的方法进行,则需要的乘法次数为m*n*p。多个矩阵相乘满足结合律,不同的乘法顺序所需要的乘法次数不同。考虑采用动态规划方法确定Mi,M(i+1),…,Mj多个矩阵连乘的最优顺序,即所需要的乘法次数最少。最少乘法次数用m[i,j]表示,其递归式定义为: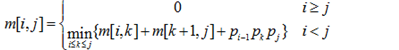 其中i、j和k为矩阵下标,矩阵序列中Mi的维度为(pi-1)*pi采用自底向上的方法实现该算法来确定n个矩阵相乘的顺序,其时间复杂度为( )
其中i、j和k为矩阵下标,矩阵序列中Mi的维度为(pi-1)*pi采用自底向上的方法实现该算法来确定n个矩阵相乘的顺序,其时间复杂度为( )
A、O(n2)
B、O(n2lgn)
C、O(n3)
D、O(n3lgn)
解析:
根据题目描述,递归式需要从i、j、k三个维度遍历,以确定多个矩阵连乘的最优顺序,因此时间复杂度为O(n^3)。所以,正确答案是C选项。
65、
两个矩阵Am*n和Bn*p相乘,用基本的方法进行,则需要的乘法次数为m*n*p。多个矩阵相乘满足结合律,不同的乘法顺序所需要的乘法次数不同。考虑采用动态规划方法确定Mi,M(i+1),…,Mj多个矩阵连乘的最优顺序,即所需要的乘法次数最少。最少乘法次数用m[i,j]表示,其递归式定义为:

其中i、j和k为矩阵下标,矩阵序列中Mi的维度为(pi-1)*pi采用自底向上的方法实现该算法来确定n个矩阵相乘的顺序,若四个矩阵M1、M2、M3、M4相乘的维度序列为2、6、3、10、3,采用上述算法求解,则乘法次数为( )。
A、156
B、144
C、180
D、360
解析:
根据题目描述,四个矩阵相乘的维度序列为2、6、3、10、3。按照算法,先计算M1M2和M3M4,计算次数分别为263=36和3103=90。然后,将两个结果相乘,计算次数为233=18。最终,乘法次数为36+90+18=144,故选项B正确。
66、以下协议中属于应用层协议的是( ),
A、SNMP
B、ARP
C、ICMP
D、X.25
解析:
SNMP(简单网络管理协议)是应用层协议,用于网络设备的管理。ARP(地址解析协议)和ICMP(Internet控制消息协议)是网络层协议,用于实现网络层的地址转换和错误报告等功能。X.25是一种标准的接口协议,用于实现分组交换网络中的数据传输。因此,只有SNMP是应用层协议。
67、SNMP属于应用层协议的该协议的报文封装在( )。
A、TCP
B、IP
C、UDP
D、ICMP
解析:
SNMP(简单网络管理协议)是一个应用层协议,用于网络设备的监控和管理。它的报文通常封装在UDP(用户数据报协议)中进行传输。因此,正确答案是C。
68、
某公司内部使用wb.xyz.com.cn作为访问某服务器的地址,其中wb是( )。
A、主机名
B、协议名
C、目录名
D、文件名
解析:
在URL(统一资源定位器)中,"wb.xyz.com.cn"作为访问某服务器的地址部分,其中的"wb"代表的是主机名。URL的一般结构为:协议://主机名.域名.域名后缀或IP地址(:端口号)/目录/文件名。因此,正确答案为A,表示"wb"是主机名。
69、
如果路由器收到了多个路由协议转发的关于某个目标的多条路由,那么决定采用哪条路由的策略是( )。
A、选择与自己路由协议相同的
B、选择路由费用最小的
C、比较各个路由的管理距离
D、比较各个路由协议的版本
解析:
路由器在处理来自多个路由协议关于某个目标的多条路由时,会根据管理距离(Administrative Distance)来决定采用哪条路由。管理距离是一个用于决定路由器应信任哪个路由协议的指标。因此,路由器会先比较各个路由的管理距离,再决定采用哪条路由。
70、
与地址220.112.179.92匹配的路由表的表项是( )。
A、220.112.145.32/22
B、220.112.145.64/22
C、220.112.147.64/22
D、220.112.177.64/22
解析:
地址220.112.179.92中的最后一部分二进制表示可以与路由表中的子网掩码进行匹配。对于选项D,子网掩码为22位,即子网前缀为220.112.177.0。将地址220.112.179.92的前缀与子网前缀进行比较,可以看出它们匹配,因此选择D作为正确答案。
71、
Software entities are more complex for
their size than perhaps any other human construct, because no two parts are
alike (at least above the statement level). If they are, we make the two
similar parts into one, a(71 ), open or closed. In this respect software systems differ
profoundly from computers,buildings, or automobiles, where repeated elements
abound.
Digital computers are themselves more
complex than most things people build; they have very large numbers of states.
This makes conceiving, describing, and testing them hard. Software systems have
orders of magnitude more (72 )than computers do.
Likewise, a scaling-up of a software entity
is not merely a repetition of the same elements in larger size; it is necessarily an increase in
the number of different elements. In most cases, the elements interact with
each other in some( 73 )fashion,and
the complexity of the whole increases much more than linearly.
The complexity of software is a(an)(74 )property, not
an accidental one. Hence descriptions of a software entity that abstract away
its complexity often abstract away its essence.Mathematics and the physical
sciences made great strides for three centuries by constructing simplified
models of complex phenomena, deriving properties from the models, and verifying
those properties experimentally. This worked because the complexities(75 )in the models
were not the essential properties of the phenomena. It does not work when the
complexities are the essence.
Many of the classical problems of
developing software products derive from this essential complexity and its nonlinear increases with
size. Not only technical problems but management problems as well come from the complexity.
作答71题
A、task
B、job
C、subroutine
D、program
解析:
根据句子结构和语境,"如果我们把两个相似的部分合并成一个,那么这个部分可能是一个子程序(subroutine)。因此,正确答案为C。其他选项如任务(task)、工作(job)、程序(program)都不符合语境。
72、Software entities are more complex for
their size than perhaps any other human construct, because no two parts are
alike (at least above the statement level). If they are, we make the two
similar parts into one, a(71 ), open or closed. In this respect software systems differ
profoundly from computers,buildings, or automobiles, where repeated elements
abound.
Digital computers are themselves more
complex than most things people build; they have very large numbers of states.
This makes conceiving, describing, and testing them hard. Software systems have
orders of magnitude more (72 )than computers do.
Likewise, a scaling-up of a software entity
is not merely a repetition of the same elements in larger size; it is necessarily an increase in
the number of different elements. In most cases, the elements interact with
each other in some( 73 )fashion,and
the complexity of the whole increases much more than linearly.
The complexity of software is a(an)(74 )property, not
an accidental one. Hence descriptions of a software entity that abstract away
its complexity often abstract away its essence.Mathematics and the physical
sciences made great strides for three centuries by constructing simplified
models of complex phenomena, deriving properties from the models, and verifying
those properties experimentally. This worked because the complexities(75 )in the models
were not the essential properties of the phenomena. It does not work when the
complexities are the essence.
Many of the classical problems of
developing software products derive from this essential complexity and its nonlinear increases with
size. Not only technical problems but management problems as well come from the complexity.
作答72题
A、states
B、parts
C、conditions
D、expressions
解析:
根据文章内容,软件系统的复杂性体现在其状态的数量上,而不是部件、条件或表达式。因此,正确答案是A,即“states(状态)”。
73、Software entities are more complex for
their size than perhaps any other human construct, because no two parts are
alike (at least above the statement level). If they are, we make the two
similar parts into one, a(71 ), open or closed. In this respect software systems differ
profoundly from computers,buildings, or automobiles, where repeated elements
abound.
Digital computers are themselves more
complex than most things people build; they have very large numbers of states.
This makes conceiving, describing, and testing them hard. Software systems have
orders of magnitude more (72 )than computers do.
Likewise, a scaling-up of a software entity
is not merely a repetition of the same elements in larger size; it is necessarily an increase in
the number of different elements. In most cases, the elements interact with
each other in some( 73 )fashion,and
the complexity of the whole increases much more than linearly.
The complexity of software is a(an)(74 )property, not
an accidental one. Hence descriptions of a software entity that abstract away
its complexity often abstract away its essence.Mathematics and the physical
sciences made great strides for three centuries by constructing simplified
models of complex phenomena, deriving properties from the models, and verifying
those properties experimentally. This worked because the complexities(75 )in the models
were not the essential properties of the phenomena. It does not work when the
complexities are the essence.
Many of the classical problems of
developing software products derive from this essential complexity and its nonlinear increases with
size. Not only technical problems but management problems as well come from the complexity.
作答73题
A、linear
B、nonlinear
C、parallel
D、additive
解析:
根据题干中的描述,软件实体的元素在大多数情况下会以某种方式相互交互,整个复杂性的增加远远超过线性增加。因此,正确答案是B,即非线性(nonlinear)。
74、Software entities are more complex for
their size than perhaps any other human construct, because no two parts are
alike (at least above the statement level). If they are, we make the two
similar parts into one, a(71 ), open or closed. In this respect software systems differ
profoundly from computers,buildings, or automobiles, where repeated elements
abound.
Digital computers are themselves more
complex than most things people build; they have very large numbers of states.
This makes conceiving, describing, and testing them hard. Software systems have
orders of magnitude more (72 )than computers do.
Likewise, a scaling-up of a software entity
is not merely a repetition of the same elements in larger size; it is necessarily an increase in
the number of different elements. In most cases, the elements interact with
each other in some( 73 )fashion,and
the complexity of the whole increases much more than linearly.
The complexity of software is a(an)(74 )property, not
an accidental one. Hence descriptions of a software entity that abstract away
its complexity often abstract away its essence.Mathematics and the physical
sciences made great strides for three centuries by constructing simplified
models of complex phenomena, deriving properties from the models, and verifying
those properties experimentally. This worked because the complexities(75 )in the models
were not the essential properties of the phenomena. It does not work when the
complexities are the essence.
Many of the classical problems of
developing software products derive from this essential complexity and its nonlinear increases with
size. Not only technical problems but management problems as well come from the complexity.
作答74题
A、surface
B、outside
C、exterior
D、essential
解析:
根据文章最后一段的描述,软件复杂性是一个本质属性,不是一个偶然的属性。因此,描述软件实体时,如果忽略了其复杂性,就会失去其本质。因此,正确答案是D,即“本质的”。
75、Software entities are more complex for
their size than perhaps any other human construct, because no two parts are
alike (at least above the statement level). If they are, we make the two
similar parts into one, a(71 ), open or closed. In this respect software systems differ
profoundly from computers,buildings, or automobiles, where repeated elements
abound.
Digital computers are themselves more
complex than most things people build; they have very large numbers of states.
This makes conceiving, describing, and testing them hard. Software systems have
orders of magnitude more (72 )than computers do.
Likewise, a scaling-up of a software entity
is not merely a repetition of the same elements in larger size; it is necessarily an increase in
the number of different elements. In most cases, the elements interact with
each other in some( 73 )fashion,and
the complexity of the whole increases much more than linearly.
The complexity of software is a(an)(74 )property, not
an accidental one. Hence descriptions of a software entity that abstract away
its complexity often abstract away its essence.Mathematics and the physical
sciences made great strides for three centuries by constructing simplified
models of complex phenomena, deriving properties from the models, and verifying
those properties experimentally. This worked because the complexities(75 )in the models
were not the essential properties of the phenomena. It does not work when the
complexities are the essence.
Many of the classical problems of
developing software products derive from this essential complexity and its nonlinear increases with
size. Not only technical problems but management problems as well come from the complexity.
作答75题
A、fixed
B、included
C、ignored
D、stabilized
解析:
根据文章第一段描述,软件的复杂性是软件的一个基本属性,而不是偶然的。因此,描述软件实体时忽略其复杂性往往会抽象掉其本质。所以正确答案是C,即“被忽略的复杂性”。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




