



分析&回答
IO多路复用
I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流。直白点说:多路指的是多个socket连接,复用指的是复用一个线程进行管理。发明它的原因,是尽量多的提高服务器的吞吐能力。
Linux IO多路复用依次出现了select、poll、epoll实现,可以认为select、poll是过期产品,现在推荐使用epoll,epoll性能比其他几者要好。
Epoll介绍
epoll是linux2.6内核的一个新的系统调用,epoll在设计之初,就是为了替代select, poll线性复杂度的模型,epoll的时间复杂度为O(1), 也就意味着,epoll在高并发场景,随着文件描述符的增长,有良好的可扩展性。
- select 和 poll 监听文件描述符list,进行一个线性的查找 O(n)
- epoll: 使用了内核文件级别的回调机制O(1)
Epoll高效原理
- 调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个RB-Tree红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件。
- 调用epoll_wait时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已。
epoll高效的本质在于:
- 减少了用户态和内核态的文件句柄拷贝
- 减少了对可读可写文件句柄的遍历
- mmap 加速了内核与用户空间的信息传递,epoll是通过内核与用户mmap同一块内存,避免了无谓的内存拷贝
- IO性能不会随着监听的文件描述的数量增长而下降
- 使用红黑树存储fd,以及对应的回调函数,其插入,查找,删除的性能不错,相比于hash,不必预先分配很多的空间
反思&扩展
IO多路复用涉及知识较多,如果你想成为你的亮点,就继续了解,如果应付问题,可以浅尝辄止。
IO多路复用模型 Reactor
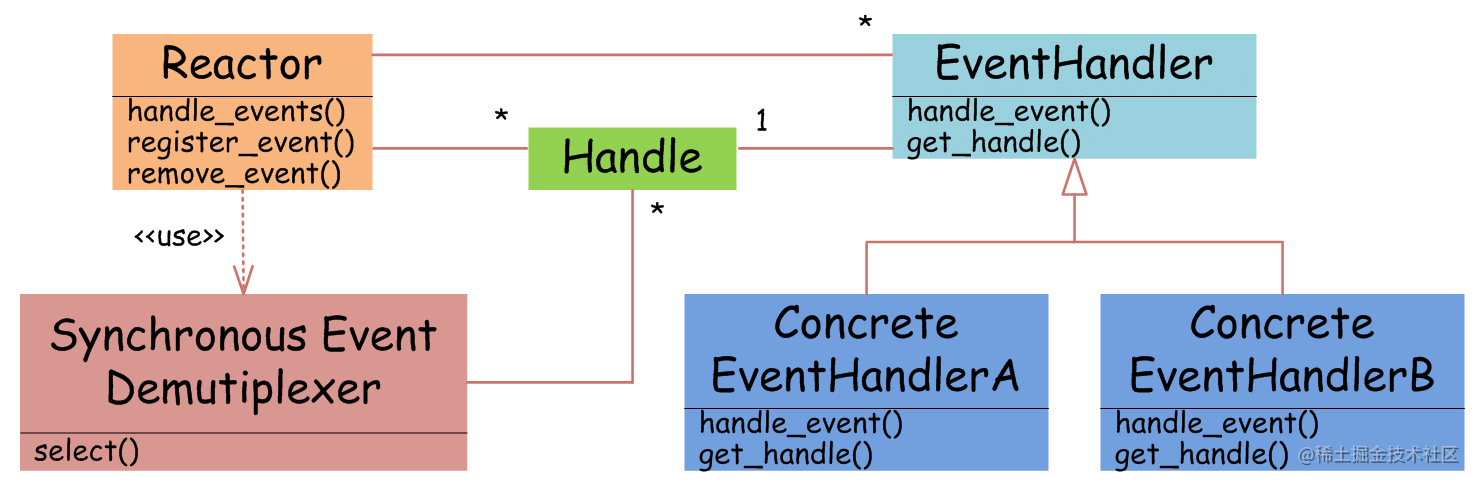
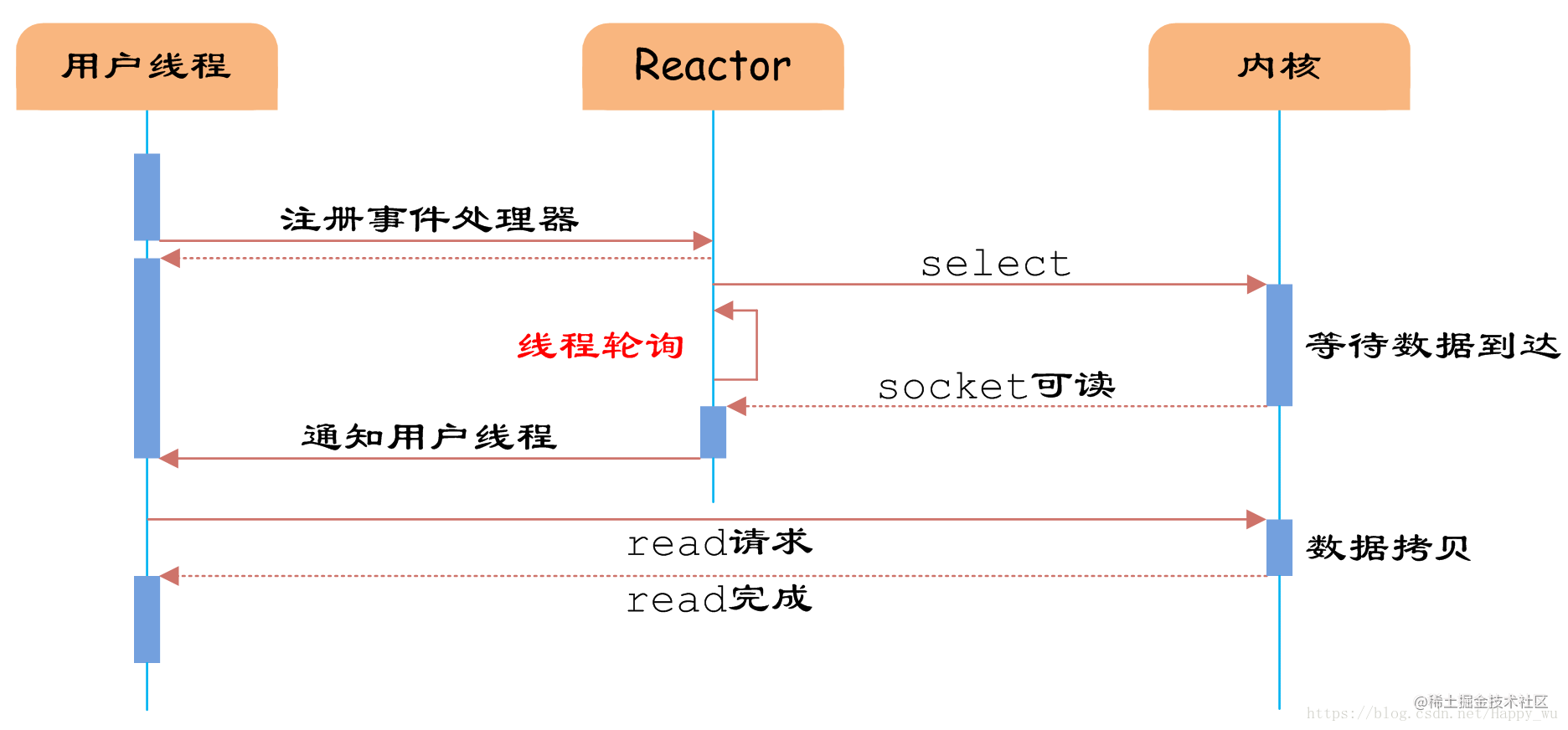
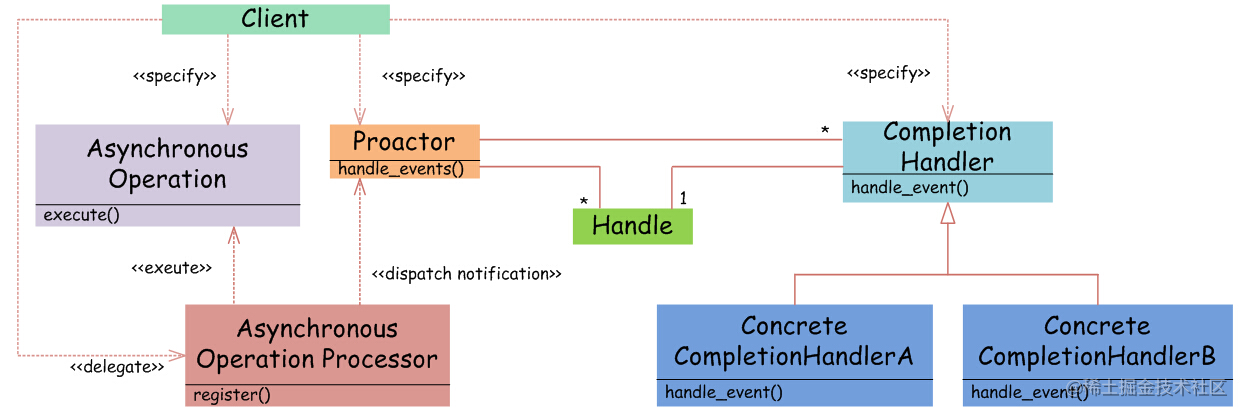
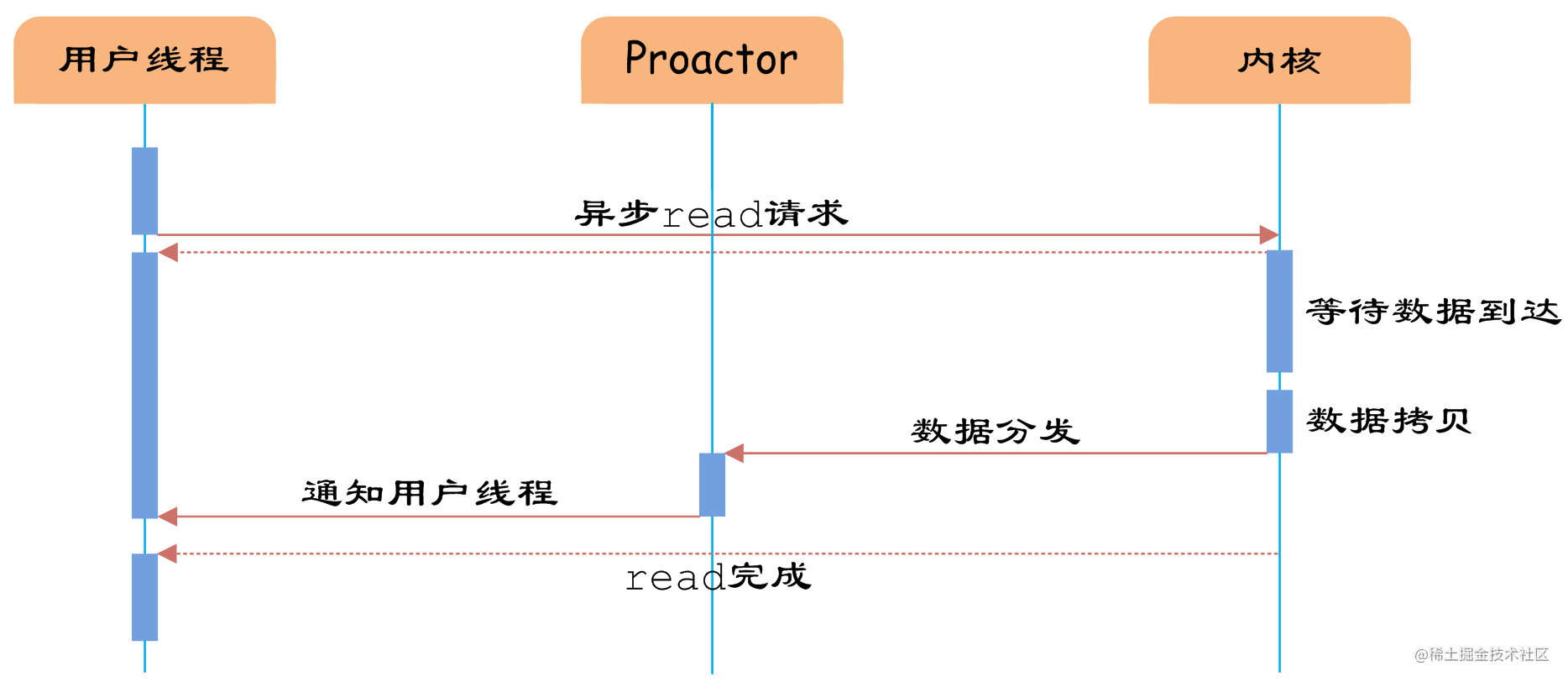
异步IO Proactor
“真正”的异步IO需要操作系统更强的支持。
Epoll事件有两种模型
边沿触发:edge-triggered (ET), 水平触发:level-triggered (LT)
- 水平触发(level-triggered)
- socket接收缓冲区不为空 有数据可读 读事件一直触发
- socket发送缓冲区不满 可以继续写入数据 写事件一直触发
- 边沿触发(edge-triggered)
- socket的接收缓冲区状态变化时触发读事件,即空的接收缓冲区刚接收到数据时触发读事件
- socket的发送缓冲区状态变化时触发写事件,即满的缓冲区刚空出空间时触发读事件
边沿触发仅触发一次,水平触发会一直触发。
喵呜刷题:让学习像火箭一样快速,快来微信扫码,体验免费刷题服务,开启你的学习加速器!




