刷题刷出新高度,偷偷领先!偷偷领先!偷偷领先! 关注我们,悄悄成为最优秀的自己!
InnoDB全文索引是如何实现的 ?
答案:
分析&回答
全文索引的底层实现为倒排索引。
为什么叫倒排索引(反向索引)
当表上存在全文索引时,就会隐式的建立一个名为FTS_DOC_ID的列,并在其上创建一个唯一索引,用于标识分词出现的记录行。你也可以显式的创建一个名为FTS_DOC_ID的列,但需要和隐式创建的列类型保持一致,否则创建的时候将会报错,并且不能通过FTS_DOC_ID来查找列:
mysql> select * from articles where FTS_DOC_ID = 1;
ERROR 1054 (42S22): Unknown column 'FTS_DOC_ID' in 'where clause'
所以建立的articles表中列为 FTS_DOC_ID、id、title、body
常规的索引是文档到关键词的映射:文档——>关键词
倒排索引是关键词到文档的映射:关键词——>文档
全文索引通过关键字找到关键字所在文档,可以提高查询效率
倒排索引结构
| Number | Text | Documents |
|---|---|---|
| 1 | code | (1:6),(4:8) |
| 2 | days | (3:2),(6:2) |
| 3 | hot | (1:3),(4:4) |
是word + ilist的存储结构
Text对应于word,是一个分词。Document存储的是键值对,键为FTS_DOC_ID,值为在文档中的位置,对应于ilist。其中word保存在Auxiliary Table中,总共有六张,每张表根据word的Latin编码进行分区,下面有介绍。
FTS Index Cache(全文检索索引缓存)
- 在事务提交的时候将分词写入到FTS Index Cache中
- 批量更新到Auxiliary Table,为了提高性能不会插入一条数据立刻更新到Auxiliary Table。进行批量更新的几种情况:
- 全文检索索引缓存已满,默认大小为32M,可以通过修改innodb_ft_cache_size来改变FTS Index Cache的大小
- 关闭数据库的时候,将FTS Index Cache中的数据库会同步到磁盘上的Auxiliary Table中
- 当对全文检索进行查询时,首先会将在FTS Index Cache中对应的字段合并到Auxiliary Table中,然后在进行查询
- 当数据库突然宕机时,可能会导致一些FTS Index Cache中的数据未同步到Auxiliary Table上。数据库重启时,当用户对表进行全文检索时,InnoDB存储引擎会自动读取未完成的文档,然后进行分词操作,在将分词的结果放入到FTS Index Cache中。innodb_ft_cache_size的大小会影响恢复的时间
- FTS Index Cache为红黑树结构,会根据(word,ilist)进行排序插入
Auxiliary Table(辅助表)
- Auxiliary Table存储在磁盘中,进入保存mysql数据的目录下(xxx/xxx/data/study)
看到有FTS_000000000000005e_0000000000000087_INDEX_0~6.ibd,其对应的就是六张Auxiliary Table
其余文件介绍:
FTS_000000000000005e_DELETED.ibd
FTS_000000000000005e_DELETED_CACHE.ibd
记录的是从Auxiliary Table中删除的FTS_DOC_ID,后者是前者的内存缓存
FTS_000000000000005e_BEING_DELETED.ibd
FTS_000000000000005e_BEING_DELETED_CACHE.ibd
记录的是已经被删除索引记录并真正从FTS Index Cache删除的FTS_DOC_ID(即删除FTS Index Cache并做了OPTIMIZE TABLE),后者是前者的内存缓存。这两个表主要用于辅助进行OPTIMIZE TABLE时将DELETED/DELETED_CACHED表中的记录转储到其中
FTS_000000000000005e_CONFIG.ibd
包含全文索引的内部信息,最重要的存储是FTS_SYNCED_DOC_ID,表示已经解析并刷到磁盘的FTS_DOC_ID, 在系统宕机时,可以根据这个值判断哪些该重新分词并加入到FTS Index Cache中
DML操作
DML 只是对表内部的数据操作,不涉及表的定义,结构的修改。 主要包括(insert)(delete)(update)(select) 删除数据库。
- 插入操作
插入操作较为简单,当往表中插入记录时,提交事务时会对全文索引上的列进行分词存储到FTS Index Cache,最后在批量更新到Auxiliary Table中 - 删除操作
当提交删除数据的事务以后,不会删除Auxiliary Table中的数据,而只会删除FTS Index Cache中的数据。对于Auxiliary Table中被删除的记录,InnoDB存储引擎会记录其FTS Document Id,并将其保存在DELETED Auxiliary Table中。可以通过OPTIMIZE TABLE手动删除索引中的记录。 - 更新操作
- 查找操作
分为两步。第一步:根据检索词搜集符合条件的FTS_DOC_ID,在搜集满足条件的FTS_DOC_ID首先读取delete表中记录的FTS_DOC_ID,这些FTS_DOC_ID随后被用做过滤
第二步:根据FTS_DOC_ID找到对应的记录,找到的记录是根据相关性大小降序返回的。
反思&扩展
说说正向索引和反向索引?
正向索引(forward index)
一般是通过key,去找value。
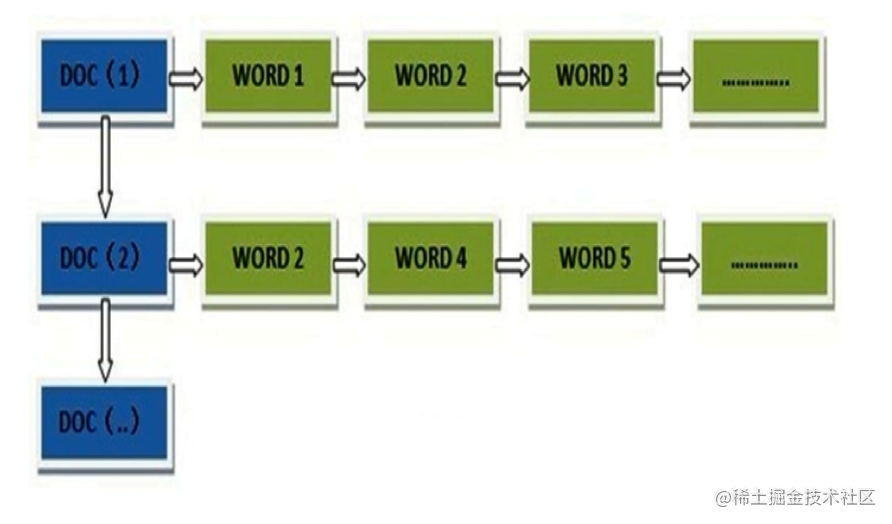
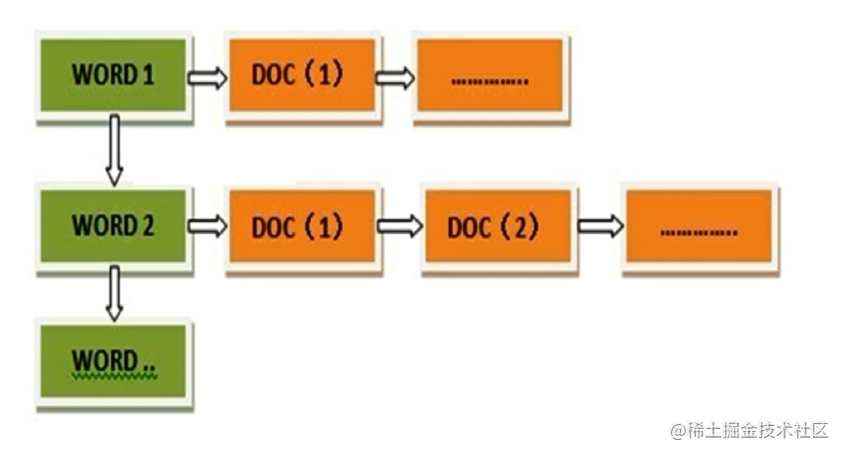
反向索引(inverted index)
从词的关键字,去找文档。
本文链接:InnoDB全文索引是如何实现的 ?
版权声明:本站点所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明文章出处。让学习像火箭一样快速,微信扫码,获取考试解析、体验刷题服务,开启你的学习加速器!




